![[SDOI2010]粟粟的书架 题解](https://ksmeow.moe/wp-content/uploads/2018/05/180524c.jpg)
[SDOI2010]粟粟的书架 题解
题目地址:洛谷:【P2468】[SDOI2010]粟粟的书架 – 洛谷、BZO …
May all the beauty be blessed.
![[JSOI2011]分特产 题解](https://ksmeow.moe/wp-content/uploads/2018/05/180524a.jpg)
题目地址:洛谷:暂无、BZOJ:Problem 4710. — [Jsoi2011]分特产
JYY 带队参加了若干场ACM/ICPC 比赛,带回了许多土特产,要分给实验室的同学们。JYY 想知道,把这些特产分给N 个同学,一共有多少种不同的分法?当然,JYY 不希望任何一个同学因为没有拿到特产而感到失落,所以每个同学都必须至少分得一个特产。
例如,JYY 带来了2 袋麻花和1 袋包子,分给A 和B 两位同学,那么共有4 种不同的分配方法:
A:麻花,B:麻花、包子
A:麻花、麻花,B:包子
A:包子,B:麻花、麻花
A:麻花、包子,B:麻花
有N个同学M种物品,每个物品有有限个,求每个同学都分到至少一个物品的方案数。
输入格式:
输入数据第一行是同学的数量N 和特产的数量M。
第二行包含M 个整数,表示每一种特产的数量。
N, M 不超过1000,每一种特产的数量不超过1000
输出格式:
输出一行,不同分配方案的总数。由于输出结果可能非常巨大,你只需要输出最终结果MOD 1,000,000,007 的数值就可以了。
输入样例#1:
5 4 1 3 3 5
输出样例#1:
384835
首先我们会发现对于每个特产分开插板处理即可。插板解决一个可空分配方案数的答案是\mathrm{C}_{n+m-1}^{m-1}。
考虑一个常规的容斥思路,即:
答案=至少0人没分到特产的方案数-至少1人没分到特产的方案数+至少2人没分到特产的方案数-……
为了保证“至少”,我们要钦定一些人不被分到,然后按照上面类似的插板思路分配剩下的人。因此最后的答案是
\sum_{i=0}^n \left[ (-1)^i \mathrm{C}_n^i \prod_{j=1}^m \mathrm{C}_{n+a_j-i-1}^{n-i-1} \right]
// Code by KSkun, 2018/5
#include <cstdio>
#include <cctype>
#include <algorithm>
typedef long long LL;
inline char fgc() {
static char buf[100000], *p1 = buf, *p2 = buf;
return p1 == p2 && (p2 = (p1 = buf) + fread(buf, 1, 100000, stdin), p1 == p2) ? EOF : *p1++;
}
inline LL readint() {
register LL res = 0, neg = 1;
register char c = fgc();
while(!isdigit(c)) {
if(c == '-') neg = -1;
c = fgc();
}
while(isdigit(c)) {
res = (res << 1) + (res << 3) + c - '0';
c = fgc();
}
return res * neg;
}
const int MAXN = 2005, MO = 1e9 + 7;
int n, m;
LL num[MAXN];
LL C[MAXN][MAXN];
inline void calc() {
C[0][0] = 1;
for(int i = 1; i < MAXN; i++) {
C[i][0] = 1;
for(int j = 1; j <= i; j++) {
C[i][j] = (C[i - 1][j - 1] + C[i - 1][j]) % MO;
}
}
}
int main() {
calc();
n = readint(); m = readint();
for(int i = 1; i <= m; i++) {
num[i] = readint();
}
LL ans = 0, t = -1;
for(int i = 0; i <= n; i++) {
t *= -1;
LL res = 1;
for(int j = 1; j <= m; j++) {
res = res * C[n + num[j] - i - 1][n - i - 1] % MO;
}
ans = (ans + t * C[n][i] * res % MO) % MO;
}
printf("%lld", (ans + MO) % MO);
return 0;
}
![[NOI2016]优秀的拆分 题解](https://ksmeow.moe/wp-content/uploads/2018/05/180522a.jpg)
题目地址:洛谷:【P1117】[NOI2016]优秀的拆分 – 洛谷、BZOJ:Problem 4650. — [Noi2016]优秀的拆分
如果一个字符串可以被拆分为 AABB 的形式,其中 A和 B是任意非空字符串,则我们称该字符串的这种拆分是优秀的。
例如,对于字符串 aabaabaa,如果令 A=aab,B=a,我们就找到了这个字符串拆分成 AABB的一种方式。
一个字符串可能没有优秀的拆分,也可能存在不止一种优秀的拆分。比如我们令 A=a,B=baa,也可以用 AABB表示出上述字符串;但是,字符串 abaabaa 就没有优秀的拆分。
现在给出一个长度为 n的字符串 S,我们需要求出,在它所有子串的所有拆分方式中,优秀拆分的总个数。这里的子串是指字符串中连续的一段。
以下事项需要注意:
问一个字符串所有子串中,能够将子串拆分成AABB的拆分方案总数。其中A、B是任意非空串,A=B同样合法。
输入格式:
每个输入文件包含多组数据。输入文件的第一行只有一个整数 T,表示数据的组数。保证 1≤T≤10。
接下来 T行,每行包含一个仅由英文小写字母构成的字符串 S,意义如题所述。
输出格式:
输出 T行,每行包含一个整数,表示字符串 S 所有子串的所有拆分中,总共有多少个是优秀的拆分。
输入样例#1:
4 aabbbb cccccc aabaabaabaa bbaabaababaaba
输出样例#1:
3 5 4 7
我们用 S[i,j]表示字符串 S第 i 个字符到第 j个字符的子串(从 1开始计数)。
第一组数据中,共有 3个子串存在优秀的拆分:
S[1,4]=aabb,优秀的拆分为 A=a,B=b;
S[3,6]=bbbb,优秀的拆分为 A=b,B=b;
S[1,6]=aabbbb,优秀的拆分为 A=a,B=bb。
而剩下的子串不存在优秀的拆分,所以第一组数据的答案是 3。
第二组数据中,有两类,总共 4 个子串存在优秀的拆分:
对于子串 S[1,4]=S[2,5]=S[3,6]=cccc,它们优秀的拆分相同,均为 A=c,B=c,但由于这些子串位置不同,因此要计算 3 次;
对于子串 S[1,6]=cccccc,它优秀的拆分有 2 种:A=c,B=cc 和 A=cc,B=c,它们是相同子串的不同拆分,也都要计入答案。
所以第二组数据的答案是 3+2=5。
第三组数据中,S[1,8] 和 S[4,11] 各有 2 种优秀的拆分,其中 S[1,8] 是问题描述中的例子,所以答案是 2+2=4。
第四组数据中,S[1,4],S[6,11],S[7,12],S[2,11],S[1,8] 各有 1种优秀的拆分,S[3,14] 有 2 种优秀的拆分,所以答案是 5+2=7。
对于全部的测试点,保证 1≤T≤10。以下对数据的限制均是对于单组输入数据而言的,也就是说同一个测试点下的 T组数据均满足限制条件。
我们假定 n 为字符串 S 的长度,每个测试点的详细数据范围见下表:
All n≤30000
参考资料:
我们考虑对于每个位置i,统计两个信息pre和suf,表示前缀i后缀为AA的个数与后缀i前缀为AA的个数。答案显然就是 \displaystyle \sum_{i=1}^n pre[i]suf[i+1]。
后缀的前缀和前缀的后缀问题显然可以用SA解决(方法参见:后缀数组(倍增)算法原理及应用 | KSkun’s Blog),但是我们需要一个统计的思路。
考虑枚举AA模式中一段A的串长k,然后在原串中每k个字符设置一个关键点,对于任意一个A串长为k的AA串,一定恰好经过两个相邻的关键点kt、k(t+1)。我们考虑求出两关键点的前缀LCS长度l和后缀LCP长度r,如果 (l+r) \geq k,则我们就找到了一个符合条件的AA串。
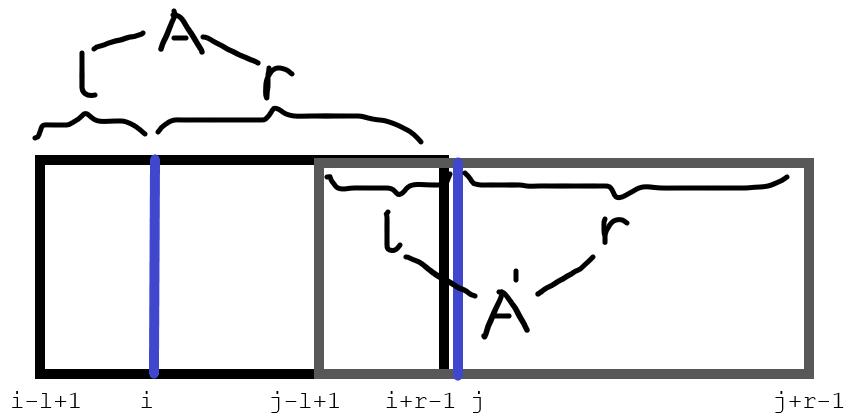
考虑找到的每个AA串对pre和suf造成的影响。设相邻的两个关键点靠前的为i,靠后的为j。能够产生AA串作为前缀的位置,这一段位置应当是[j-l+k, j+r-1]。对应示例图,我们可以发现这段区间对应的是A’这个串第k个字符到末尾,这是由于A部分此时至少要保留[i-l+1, j-l-1]这一段,也就对应A’部分的[i-l+k+1, j-l+k-1]一段。而作为后缀的位置是[i-l+1, i+r-k],原理相同。那么实际上每次的操作就是对pre、suf中连续一段区间+1,可以将操作差分降低复杂度。
这样一通操作下来的复杂度实际上是O(Tn \log n)的,数据范围不是很卡。
// Code by KSkun, 2018/5
#include <cstdio>
#include <cctype>
#include <cstring>
#include <algorithm>
typedef long long LL;
const int MAXN = 100005;
int Log2[MAXN];
inline void callog2() {
for(int i = 2; i < MAXN; i++) {
Log2[i] = Log2[i >> 1] + 1;
}
}
struct SuffixArray {
char s[MAXN];
int n, m, sa[MAXN], t[MAXN], t1[MAXN], c[MAXN], rnk[MAXN], hei[MAXN], st[MAXN][25];
inline void init() {
memset(this, 0, sizeof(SuffixArray));
}
inline void calsa() {
int *x = t, *y = t1;
for(int i = 1; i <= m; i++) c[i] = 0;
for(int i = 1; i <= n; i++) c[x[i] = s[i]]++;
for(int i = 1; i <= m; i++) c[i] += c[i - 1];
for(int i = n; i >= 1; i--) sa[c[x[i]]--] = i;
for(int k = 1; k <= n; k <<= 1) {
int p = 0;
for(int i = n - k + 1; i <= n; i++) y[++p] = i;
for(int i = 1; i <= n; i++) if(sa[i] > k) y[++p] = sa[i] - k;
for(int i = 1; i <= m; i++) c[i] = 0;
for(int i = 1; i <= n; i++) c[x[y[i]]]++;
for(int i = 1; i <= m; i++) c[i] += c[i - 1];
for(int i = n; i >= 1; i--) sa[c[x[y[i]]]--] = y[i];
std::swap(x, y);
p = x[sa[1]] = 1;
for(int i = 2; i <= n; i++) {
x[sa[i]] = (y[sa[i - 1]] == y[sa[i]] && y[sa[i - 1] + k] == y[sa[i] + k])
? p : ++p;
}
if(p >= n) break;
m = p;
}
memcpy(rnk, x, sizeof(rnk));
int k = 0;
for(int i = 1; i <= n; i++) {
int j = sa[rnk[i] + 1];
if(k) k--;
if(!j) continue;
while(s[i + k] == s[j + k]) k++;
hei[rnk[i]] = k;
}
}
inline void calst() {
for(int i = 1; i <= n; i++) {
st[i][0] = hei[i];
}
for(int i = 1; i <= 20; i++) {
for(int j = 1; j + (1 << i) <= n; j++) {
st[j][i] = std::min(st[j][i - 1], st[j + (1 << (i - 1))][i - 1]);
}
}
}
inline int querylcp(int x, int y) {
x = rnk[x]; y = rnk[y];
if(x > y) std::swap(x, y);
int t = Log2[y - x];
return std::min(st[x][t], st[y - (1 << t)][t]);
}
} saa, sab;
int T, n, pre[MAXN], suf[MAXN];
inline int lcp(int x, int y) {
return saa.querylcp(x, y);
}
inline int lcs(int x, int y) {
return sab.querylcp(n - x + 1, n - y + 1);
}
int main() {
callog2();
scanf("%d", &T);
while(T--) {
saa.init(); sab.init();
memset(pre, 0, sizeof(pre));
memset(suf, 0, sizeof(suf));
saa.m = sab.m = 256;
scanf("%s", saa.s + 1);
saa.n = sab.n = n = strlen(saa.s + 1);
for(int i = 1; i <= n; i++) {
sab.s[i] = saa.s[n - i + 1];
}
saa.calsa(); saa.calst();
sab.calsa(); sab.calst();
for(int k = 1; k <= n >> 1; k++) {
for(int i = k, j = i + k; j <= n; i += k, j += k) {
int l = std::min(lcs(i - 1, j - 1), k - 1), r = std::min(lcp(i, j), k);
if(l + r >= k) {
pre[j - l + k - 1]++; pre[j + r]--;
suf[i - l]++; suf[i + r - k + 1]--;
}
}
}
for(int i = 1; i <= n; i++) {
pre[i] += pre[i - 1];
suf[i] += suf[i - 1];
}
LL ans = 0;
for(int i = 1; i <= n; i++) {
ans += 1ll * pre[i] * suf[i + 1];
}
printf("%lld\n", ans);
}
return 0;
}
![[HAOI2007]修筑绿化带 题解](https://ksmeow.moe/wp-content/uploads/2018/05/180519b.jpg)
题目地址:洛谷:【P2219】[HAOI2007]修筑绿化带 – 洛谷
为了增添公园的景致,现在需要在公园中修筑一个花坛,同时在画坛四周修建一片绿化带,让花坛被绿化带围起来。
如果把公园看成一个M*N的矩形,那么花坛可以看成一个C*D的矩形,绿化带和花坛一起可以看成一个A*B的矩形。
如果将花园中的每一块土地的“肥沃度”定义为该块土地上每一个小块肥沃度之和,那么,
绿化带的肥沃度=A*B块的肥沃度-C*D块的肥沃度
为了使得绿化带的生长得旺盛,我们希望绿化带的肥沃度最大。
给一个M*N矩阵,要求找到一个大小为A*B的子矩阵和这个子矩阵内部一个大小为A*B的子矩阵(该子矩阵不得与外部矩阵边界有交集)使得矩阵和之差最大。
输入格式:
第一行有6个正整数M,N,A,B,C,D
接下来一个M*N的数字矩阵,其中矩阵的第i行j列元素为一个整数Xij,表示该花园的第i行第j列的土地“肥沃度”。
输出格式:
一个正整数,表示绿化带的最大肥沃程度。
输入样例#1:
4 5 4 4 2 2 20 19 18 17 16 15 14 13 12 11 10 9 8 7 6 5 4 3 2 1
输出样例#1:
132
数据范围
30%的数据,1<=M,N<=50
100%的数据,1<=M,N<=1000,1<=A<=M,1<=B<=N,1<=C<=A-2,1<=D<=B-2,1<=“肥沃度”<=100
参考资料:[HAOI2007] 修筑绿化带 – CSDN博客
我们可以先处理出每一个宽度为C的行中,每一个右端点i对应的区间[i-B+1, i]中的最小C*D矩阵。这个处理极值显然可以用单调队列实现O(n^2)的处理。
接下来的思路,就是利用我们上面准备好的这个信息来求答案,我们枚举每一列,利用单调队列和上面预处理的信息,我们可以计算出以枚举到的当前行以上不超过A行的C*D矩阵的最小值。也就是说,我们现在正在竖着枚举A*B矩阵,并用单调队列来取出矩阵内的C*D子矩阵的最小值,最后算一波差值更新答案即可。这里的复杂度也是O(n^2),因此整体复杂度O(n^2)。
比较麻烦的单调队列套路题。
// Code by KSkun, 2018/5
#include <cstdio>
#include <cctype>
#include <cstring>
#include <algorithm>
typedef long long LL;
inline char fgc() {
static char buf[100000], *p1 = buf, *p2 = buf;
return p1 == p2 && (p2 = (p1 = buf) + fread(buf, 1, 100000, stdin), p1 == p2) ? EOF : *p1++;
}
inline LL readint() {
register LL res = 0, neg = 1;
register char c = fgc();
while(!isdigit(c)) {
if(c == '-') neg = -1;
c = fgc();
}
while(isdigit(c)) {
res = (res << 1) + (res << 3) + c - '0';
c = fgc();
}
return res * neg;
}
const int MAXN = 1005;
int n, m, a, b, c, d, sum[MAXN][MAXN], mn[MAXN][MAXN];
inline int queryab(int x, int y) {
return sum[x][y] - sum[x - a][y] - sum[x][y - b] + sum[x - a][y - b];
}
inline int querycd(int x, int y) {
return sum[x][y] - sum[x - c][y] - sum[x][y - d] + sum[x - c][y - d];
}
int que[MAXN], ql, qr;
int main() {
n = readint(); m = readint();
a = readint(); b = readint();
c = readint(); d = readint();
for(int i = 1; i <= n; i++) {
for(int j = 1; j <= m; j++) {
sum[i][j] = readint() + sum[i - 1][j] + sum[i][j - 1] - sum[i - 1][j - 1];
}
}
memset(mn, 0x3f, sizeof(mn));
for(int i = c; i <= n; i++) {
ql = qr = 0;
for(int j = d; j <= m; j++) {
while(ql < qr && que[ql] - d + 1 <= j - b + 1) ql++;
if(ql < qr) {
mn[i][j] = querycd(i, que[ql]);
}
while(ql < qr && querycd(i, que[qr - 1]) >= querycd(i, j)) qr--;
que[qr++] = j;
}
}
int ans = 0;
for(int i = d; i <= m; i++) {
ql = qr = 0;
for(int j = c; j <= n; j++) {
while(ql < qr && que[ql] - c + 1 <= j - a + 1) ql++;
if(ql < qr && j >= a && i >= b) {
ans = std::max(ans, queryab(j, i) - mn[que[ql]][i]);
}
while(ql < qr && mn[que[qr - 1]][i] >= mn[j][i]) qr--;
que[qr++] = j;
}
}
printf("%d", ans);
return 0;
}
Copyright © 2017-2022 KSkun's Blog.
Authored by KSkun and his friends.

本博客内所有原创内容采用知识共享署名-相同方式共享 4.0 国际许可协议进行许可。引用内容如果侵权,请在此留言。
All original content in this blog is licensed under a Creative Commons Attribution-ShareAlike 4.0 International License.
If any reference content infringes your rights, please contact us.
![[BZOJ3697]采药人的路径 题解](https://ksmeow.moe/wp-content/uploads/2018/05/180524b.jpg)
![[洛谷1822]魔法指纹 题解](https://ksmeow.moe/wp-content/uploads/2018/05/180522c.jpg)
![[洛谷3396]哈希冲突 题解](https://ksmeow.moe/wp-content/uploads/2018/05/180522b.jpg)

![[SCOI2009]生日礼物 题解](https://ksmeow.moe/wp-content/uploads/2018/05/180519c.jpg)
![[WC2011]最大XOR和路径 题解](https://ksmeow.moe/wp-content/uploads/2018/05/180519a.jpg)