
NTP 网络时间协议
By KSkun, 2020/7/20 NTP(Network Time Procotol …
May all the beauty be blessed.
![[CSP-S2 2019]树的重心 题解](https://ksmeow.moe/wp-content/uploads/2020/05/shirobako2-6.jpg)
题目地址:洛谷:P5666 树的重心 – 洛谷 | 计算机科学教育新生态
小简单正在学习离散数学,今天的内容是图论基础,在课上他做了如下两条笔记:
课后老师给出了一个大小为 $n$ 的树 $S$,树中结点从 $1 \sim n$ 编号。小简单的课后作业是求出 $S$ 单独删去每条边后,分裂出的两个子树的重心编号和之和。即:
$$ \sum\limits_{(u,v) \in E} \left( \sum\limits_{1 \leq x \leq n \atop 且 x 号点是 S’_u 的重心} x + \sum\limits_{1 \leq y \leq n \atop 且 y 号点是 S’_v 的重心} y \right) $$
上式中,$E$ 表示树 $S$ 的边集,$(u,v)$ 表示一条连接 $u$ 号点和 $v$ 号点的边。$S’_u$ 与 $S’_v$ 分别表示树 SSS 删去边 $(u,v)$ 后,$u$ 号点与 $v$ 号点所在的被分裂出的子树。
小简单觉得作业并不简单,只好向你求助,请你教教他。
给定一棵 $n$ 个点的树,求树上每一条边 $(u,v)$ 删去后得到两个子树的所有重心编号之和。
输入格式:
本题包含多组测试数据
第一行一个整数 $T$ 表示数据组数。
接下来依次给出每组输入数据,对于每组数据:
第一行一个整数 $n$ 表示树 $S$ 的大小。
接下来 $n-1$ 行,每行两个以空格分隔的整数 $u_i, v_i$,表示树中的一条边 $(u_i,v_i)$。
输出格式:
共 $T$ 行,每行一个整数,第 $i$ 行的整数表示:第 $i$ 组数据给出的树单独删去每条边后,分裂出的两个子树的重心编号和之和。
输入样例 #1:
2 5 1 2 2 3 2 4 3 5 7 1 2 1 3 1 4 3 5 3 6 6 7
输出样例 #1:
32 56
| 测试点编号 | $n=$ | 特殊性质 |
|---|---|---|
| $1 \sim 2$ | 7 | 无 |
| $3 \sim 5$ | 199 | 无 |
| $6 \sim 8$ | 1999 | 无 |
| $9 \sim 11$ | 49991 | A |
| $12 \sim 15$ | 262143 | B |
| $16$ | 99995 | 无 |
| $17 \sim 18$ | 199995 | 无 |
| $19 \sim 20$ | 299995 | 无 |
表中特殊性质一栏,两个变量的含义为存在一个 $1 \sim n$ 的排列 $p_i \ (1 \leq i \leq n)$,使得:
对于所有测试点:$1 \leq T \leq 5 , 1 \leq u_i,v_i \leq n$。保证给出的图是一个树。
参考资料:
可能用到的记号:
拿到这个题目之后,第一个想法是枚举树上的每条边,其两端点对应的子树在树的 DFS 分别对应一个和最多两个区间。对于有根树而言,求子树中重心,就相当于求子树中最大儿子大小 $f(u)=\max\limits_{v \in \mathrm{son}(u)}\{ \mathrm{size}(v) \}$ 与父节点对应子树大小 $g(u)=n-\mathrm{size}(u)$ 二者中较大值的最小值 $\min\limits_{u \in \boldsymbol{V}(S)} \{ \max\{f(u),g(u)\} \}$ 对应的点 $u$。但这种想法情况众多,因为删边会影响两端点对应子树的 $f$ 值和 $g$ 值,它们的处理比较麻烦,目前为止并没能研究出来。
接下来要介绍的是一种「正难则反」的方法,即枚举边不是好做的方法,则枚举点,考虑其作为某种情况中的重心的次数。
下文中会以如 #标记 1# 的形式进行标记以建立上下文描述与实现代码之间的联系,请合理利用标记。
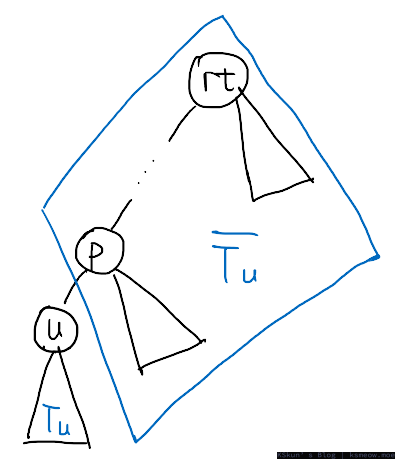
当 $u$ 不是根时,如上图,要让点 $u$ 成为某种情况下的重心,假设 $u$ 的所有儿子对应的子树 $\boldsymbol{T}(u)$ 都满足要求,只需要在除 $u$ 对应子树的部分 $\overline{T(u)}$ 删去一条边减小它的大小即可。记 $u$ 对应子树大小 $p=\mathrm{size}(u)$,$u$ 的最大儿子对应子树大小 $q=\mathrm{size}[\mathrm{mxson}(u)]$,删去一条边后从 $\overline{T(u)}$ 中移除的子树大小为 $r$。根据重心的定义,有以下条件成立:
$$ \begin{cases}
n-r-p \leq \left\lfloor \dfrac{n-r}{2} \right\rfloor, & u 的父亲对应的子树(即 \overline{T(u)} \backslash T(o))满足重心定义, \\
q \leq \left\lfloor \dfrac{n-r}{2} \right\rfloor, & u 的最大儿子对应子树满足重心定义.
\end{cases} $$
将分母的 2 乘到另一边上,再将 $r$ 单独整理出来,可以得到下式
$$ n – 2p \leq r \leq n – 2q $$
当 $r$ 不包括 $u$ 到树根路径(即图中的链 $rt, \dots, p$)上的点时,记删掉的边中远离 $u$ 的端点为 $o$,则$r = \mathrm{size}(o)$,因此只要构建出 $\overline{T(u)}$ 所有点 $\mathrm{size}$ 值的权值线段树或权值树状数组,就能很方便地查到落在区间 $[n-2p, n-2q]$ 区间内的 $r$ 值有多少个,而这就是 $u$ 点作为重心的情况数。#标记 1#
但 $r$ 也有可能包括 $u$ 到树根路径上的点,记删掉的边为 $(o_1, o_2)$,其中 $o_1$ 离 $u$ 更近,而 $o_2$ 离 $u$ 更远(即这条边在 $u$ 到树根的链上,且 $o_1$ 比 $o_2$ 更深),此时对应的删掉的子树大小应该为 $n-\mathrm{size}(o_1)$。在上文提到的树状数组中,应当删去 $\mathrm{size}(o_2)$ 一项,而加入 $[n-\mathrm{size}(o_1)]$ 一项。这个修正可以在 DFS 计算树状数组时维护好。#标记 2#
如果每次枚举一个点 $u$ 都动态地处理出所需的树状数组,复杂度不是很优,因此可以采用预先对原树全树的 $\mathrm{size}$ 值建树状数组,之后再排除 $u$ 对应子树中被错误统计进去的答案。实现排除错误答案可以用一个 DFS 进行计算,动态地往一个树状数组里添加 $\mathrm{size}$ 值,在 DFS 进入 $u$ 的子树前记下此时的答案,$u$ 子树计算完成后再记下此时的答案,前后答案之差即为 $u$ 点的错误答案,从 $u$ 作为重心的次数里减去这一错误情况即可。在这个 DFS 中,上一段中的修正(#标记 2#)也可以同时进行。#标记 3#
接下来分析上述方法的正确性。上述方法需要假定 $u$ 的所有儿子对应的子树 $\boldsymbol{T}(u)$ 都满足 $u$ 是重心时的要求,为了实现这一要求,必须有 $n-\mathrm{size}(u) \geq \mathrm{size}[\mathrm{mxson}(u)]$ 总是成立。不妨以全树的重心为根,这样就有 $\mathrm{size}(u) \leq \lfloor n/2 \rfloor$ 总是成立,而上式同时成立。这样就能保证当 $u$ 是重心时删掉的边一定不在 $u$ 的子树中,而是在 $\overline{T(u)}$ 中,实现了统计答案的不重不漏。
而上述方法带来了一个麻烦,记树根为 $rt$,该点的答案无法如上计算,因为该点对应的 $\overline{T(rt)} = \emptyset$,需要删掉的边一定在 $rt$ 的子树中。
不妨把情况分为要切掉的子树在根的最大儿子子树中和不在最大儿子子树中,分别讨论。记最大儿子子树大小为 $s_1=\mathrm{size}[\mathrm{mxson}(rt)]$,次大儿子子树大小为 $s_2$,删边后移除的子树大小为 $r$。
当切掉后的最大儿子子树大小 $s’_1=s_1-r$ 仍不小于次大儿子子树大小,即 $s’_1 \geq s_2 \Rightarrow r \leq s_1 – s_2$ 时,$rt$ 仍然是此时树的重心。下面证明这一结论,已知 $s_1 \leq \lfloor n/2 \rfloor \Rightarrow 2s_1 \leq n$,要证 $s_1 – r \leq \lfloor (n-r)/2 \rfloor \Rightarrow 2s_1 \leq n + r$,由于 $r>0$,待证式显然成立。
$s’_1<s_2$ 时,原来的次大儿子子树就变成了现在的最大儿子子树,必须满足 $s_2 \leq \lfloor (n-r)/2 \rfloor$,即 $s_1 – s_2 < r \leq n – 2s_2$。
综上,要使 $rt$ 仍是树的重心,必须满足 $r \leq n-2s_2$,可以最后单独对最大儿子子树 DFS,暴力判断每个点的 $\mathrm{size}$ 值是否满足要求即可。#标记 4#
最大儿子子树必须满足 $s_1 \leq \lfloor (n-r)/2 \rfloor$,即 $r \leq n – 2s_1$。可以和上面相似地,单独 DFS 暴力统计这些子树中每个点的 $\mathrm{size}$ 值是否满足要求。#标记 5#
到此为止,我们推出了本题所有情况的解法,下面整理一下思路,便于实现。
首先,由于解法中需要使用子树大小、最大儿子子树、根的次大儿子子树这些信息,可以用一个 DFS 计算出所有这些信息。有了子树大小信息,找出全树重心也不是难事。需要注意,在找出重心后,由于换根,这些信息还需要以重心为根重新计算一遍。
有了信息之后,就可以计算除了根之外的答案。用一个数组存储每个点作为重心的次数,用 DFS 计算答案。首先根据上文描述(#标记 2#),我们需要修正树状数组中当前点 $u$ 父节点的 $\mathrm{size}$ 为 $[n-\mathrm{size}(u)]$,然后查询区间落在 $[n-2\mathrm{size}(u), n-2\mathrm{size}[\mathrm{mxson}(u)]]$ 中的 $\mathrm{size}$ 值(#标记 1#)。另外为了排除错误情况,需要另开一个树状数组动态维护 $\mathrm{size}$ 值,错误情况数就是 DFS 深入儿子前后的答案之差,计算并修正答案即可(#标记 3#)。
下一步,计算根的答案。利用一个 DFS,在根的最大儿子子树中找到落在 $[1, n-2\mathrm{s_2}]$ 之内的 $\mathrm{size}$ 值数量(#标记 4#),和根的其他儿子子树中落在 $[1, n-2\mathrm{s_1}]$之内的 $\mathrm{size}$ 值数量(#标记 5#),两者之和便是根的答案。
最后,将出现次数与点的编号相乘加和就可得到最终答案。需要注意的是,答案可能过大,需要用 long long 存储与输出。
上述过程中,我们使用了一共三个 DFS,其中处理子树大小等信息的 DFS 复杂度为 $O(n)$,利用树状数组求根以外点答案的 DFS 复杂度为 $O(n \log n)$,求根答案的 DFS 复杂度为 $O(n)$,因此总复杂度为 $O(n \log n)$。
由于用 vector 存图,只有开 O2 能过。
// Code by KSkun, 2020/5
#include <cstdio>
#include <cctype>
#include <cstring>
#include <algorithm>
#include <utility>
#include <vector>
typedef unsigned long long LL;
typedef std::pair<int, int> PII;
using std::vector;
inline char fgc() {
static char buf[100000], *p1 = buf, *p2 = buf;
return p1 == p2 && (p2 = (p1 = buf) + fread(buf, 1, 100000, stdin), p1 == p2)
? EOF : *p1++;
}
inline LL readint() {
register LL res = 0, neg = 1; register char c = fgc();
for (; !isdigit(c); c = fgc()) if (c == '-') neg = -1;
for (; isdigit(c); c = fgc()) res = res * 10 + c - '0';
return res * neg;
}
inline char readsingle() {
char c;
while (!isgraph(c = fgc())) {}
return c;
}
const int MAXN = 300005;
// siz: 子树大小, mx_ch: 最大子树, mx2_1ch: 树根的次大子树, cnt: 作重心的次数
int T, n, ct, siz[MAXN], mx_ch[MAXN], mx2_1ch, cnt[MAXN];
vector<int> G[MAXN];
// 树状数组
class BinaryIndexedTree {
private:
int n, dat[MAXN];
int lowbit(int x) {
return x & -x;
}
public:
void init(int _n) {
n = _n;
memset(dat, 0, sizeof(dat));
}
void add(int idx, int val) {
if (idx <= 0) return;
for (int i = idx; i <= n; i += lowbit(i)) dat[i] += val;
}
int query(int idx) {
if (idx <= 0) return 0;
int res = 0;
for (int i = idx; i > 0; i -= lowbit(i)) res += dat[i];
return res;
}
} tree1, tree2;
// DFS 处理全树重心、子树大小、最大子树和树根的次大子树
void dfs_siz(int u, int par) {
siz[u] = 1;
mx_ch[u] = 0;
for (int v : G[u]) {
if (v == par) continue;
dfs_siz(v, u);
siz[u] += siz[v];
if (siz[mx_ch[u]] <= siz[v]) {
if (u == ct) mx2_1ch = mx_ch[u];
mx_ch[u] = v;
} else if (u == ct && siz[mx2_1ch] <= siz[v]) {
mx2_1ch = v;
}
}
if (siz[mx_ch[u]] <= n / 2 && n - siz[u] <= n / 2) ct = u;
}
// DFS 计算根之外点的次数
void dfs_cal(int u, int par) {
tree1.add(siz[par], -1); // 修正到根路径上各边两端子树大小 #标记 2#
tree1.add(n - siz[u], 1);
cnt[u] = tree1.query(n - 2 * siz[mx_ch[u]]) - tree1.query(n - 2 * siz[u] - 1); // #标记 1#
int bef = tree2.query(n - 2 * siz[mx_ch[u]]) - tree2.query(n - 2 * siz[u] - 1); // #标记 3# DFS 进入子树前
for (int v : G[u]) {
if (v == par) continue;
dfs_cal(v, u);
}
tree2.add(siz[u], 1);
int aft = tree2.query(n - 2 * siz[mx_ch[u]]) - tree2.query(n - 2 * siz[u] - 1);
cnt[u] -= aft - bef; // 用算子树前后 tree2 值的变化来计算子树中算入的情况 #标记 3#
tree1.add(siz[par], 1); // 消除修正的影响 #标记 2#
tree1.add(n - siz[u], -1);
}
// DFS 处理树根的方案
void dfs_rt(int u, int par, int lim) {
if (siz[u] <= lim) cnt[ct]++;
for (int v : G[u]) {
if (v == par) continue;
dfs_rt(v, u, lim);
}
}
int main() {
T = readint();
while (T--) {
// 输入
n = readint();
for (int i = 1; i <= n; i++) G[i].clear();
for (int i = 1, u, v; i <= n - 1; i++) {
u = readint(); v = readint();
G[u].push_back(v);
G[v].push_back(u);
}
// 预处理子树大小的权值树状数组
dfs_siz(1, 0); // 计算重心
dfs_siz(ct, 0); // 以重心为根计算树信息
tree1.init(n);
for (int i = 1; i <= n; i++) tree1.add(siz[i], 1);
tree2.init(n); // 计算除根之外点的次数
dfs_cal(ct, 0);
// 计算树根作重心的次数
cnt[ct] = 0;
dfs_rt(mx_ch[ct], ct, n - 2 * siz[mx2_1ch]); // 在根的最大子树中删边 #标记 4#
for (int ch : G[ct]) {
if (ch == mx_ch[ct]) continue;
dfs_rt(ch, ct, n - 2 * siz[mx_ch[ct]]); // 在根的其他子树中删边 #标记 5#
}
LL ans = 0;
for (int i = 1; i <= n; i++) ans += (LL) i * cnt[i];
printf("%lld\n", ans);
}
return 0;
}
这是一篇 KSkun 的 2019 年终总结,以记流水账的方式记录了 KSkun 在 2019 年的轨迹。
谨以此文献给这个世界。
2019 年的上半年,准确地说,6 月 8 日之前的这一段时间,是我在高中的最后半年。停课导致的能力低下问题一直困扰着整个高三,2018 年和 2019 年的唯一区别是,2018 年的时候我还熬得住,而 2019 年,我撑不下去了。
论知识体系,我不认为停课对我的高中知识体系造成了多大的影响,从这个意义上讲,停课的影响是很有限的。但缺少了相当长一段时间的重复训练,做题的速度和直觉是要远不如旁人的,这给了我很大的压力。做题不快,作业又多,直接导致了我每天的作业几乎都在欠交。尽管我的策略是写不完就不写了,老师也都习惯并接受了,我自己还是因为这一点有一些压力,或者说不安。毕竟高考时还是需要速度的,这会速度起不来,高考的时候估计要命。
作业只用在学校的时间写,一般不带回家。在家主要是整理数理化生错题,进行汇总,如果还有时间则再做重写和反思的工作。这部分是相当耗时的,因为我的错题有点多,加上改错本来就是比做题费劲一些的。22 点下课,到家往往都要 22:40,再做一些轻微运动,吃点夜宵,做一些改错,很容易跨天到第二天 1 点去了。第二天又要 6 点左右起床。每个月这么熬 “166”,身体绝对吃不消。在我批判着这么做不科学,会把学生累坏的时候,自己先不行了。
其结果是,离高考最近的大约一个月,我上午的课几乎没有出勤过,完全睡过去了,怎么也起不来床。我想这大概是身体在抗议吧。总之睡得蛮爽的,后面精神也比熬着的时候好了不少。如果这能够改善我在高考的时候的状态,这也是值得的,当时的我是这么想的。但和旁人的差距一直是一个我没能卸下来的压力。
5 月初,《明日方舟》开服。天天听周围的 wyx、zcr 等聊这个,刚开始几天还抗拒说我不玩游戏的,结果就真香了。记不住干员的名字的时候聊天真尴尬,不过美术真的很赞,游戏体验也不错。无论是作为放学后回家的放松方式,还是晚饭时的聊天谈资,《明日方舟》真的成为了高三时的一种很有效的减压方式。德克萨斯天下第一!
高三和 OI 依然保持着联系,偶尔组一组模拟题给学弟们写,补课的时候下楼到机房里看看他们写题,午晚饭时间偶遇谈起那些题目和娱乐的事情,算是 OI 带给我的额外的快乐。此外,退役 OIer 文化课交流群及其他的一些 OIer 圈子也是我这段时间经常水的地方。不过群确实水的比较多,有颓废的嫌疑了。不知道为什么突然就当上了管理,感谢大家这段时间支持我啦。
结果论而言,我的高考对于班主任对我的期望或我自己的预设目标来说都是不太行的。毕竟高三开学时信誓旦旦地说,再不济华科 CS 保底,结果考了个不太稳 CS 的分,果然还是太菜了。不过后面发生了很多好事,让我觉得这样的结果并不算太坏。
为什么一个 block 就写了这么长呢?
暑假的开始是自招,我报名了交大、北航和浙大,最后因为时间冲突选择了交大和北航。交大先开始,因此早早地去了上海。这是我人生中第一次去上海,闵行虽远,也不算太荒,还是可以找到一些商业繁华区,因此其实城市化气息挺浓重的。上海最吸引我的特点就是城市化与有序,这两点在最初的这一次旅行便感受到了。
回到自招本身,数学物理两门的笔试让我只能爬,你对一个停课的人说要考数理,这等于判他死刑(当然这只是因为我菜,我不该找借口的),因此凉了。不过见到了 panda 大爷、M 晓、Antileaf 等人,还算开心。无所谓,本就对自招没报太大希望,结果如何都无所谓。因此赶紧去了北京考北航的。
可惜的是,北航依旧逃不开数物两门,只多了个面试环节。面试的老师对着我的自我介绍提问,自我介绍里着重突出的竞赛和工程并不是吹的,因此对答没什么大问题,反而是被问到了吹学校中的一段里“北航有丰富的资源”如何理解,让我难以回答。实话说,我真的不是那么了解各个学校的详细情况,对于华科而言,直至今日也还算了解了一点点。总之也凉了。
凉就凉呗,我爬还不行吗。于是高考出了个分,考的一般般,预料之中。头一铁,华科放第一,专业依次排开,剩下的总之填满就行了,没几下志愿就报完了,这倒是很容易的事。感觉报志愿花钱买指导有点智商税。
然后去了上海看 BML,实际上还干了好多其他的事情。《明日方舟》的线下联动、《游戏人生 零》引进补票、BML 的 VR 和 SP 两场与和沙雕网友的娱乐,真的是超级开心的回忆。后来我不但打 uno 上瘾,还专门去学了一下简单的日式应援,买的一根电光棒也留到了现在,后来还用了一次。我喜欢体验我喜欢的东西,体验未知,在这之后,我觉得我应该永远尝试体验未知,走出自己的 comfort zone,去参与到这个世界的各种事件里去。BML 游记是写了的,可以看这里。
可是从上海回十堰的火车上,我查到了我的录取信息。我没能录取到 CS 或网安,而是录取到了光电院。那种“保底也是个 HUST 的 CS”的自信,被现实击碎了。那种强烈的冲动不断鼓励我说,你需要转专业,你需要读 CS。火车上是很无聊的,因此有了深入思考这件事情以及向其他人征求意见的时间和精力,经过了一番挣扎与被说服的过程,我最终接受了一切的可能性,并决心直面当下,仅考虑当下我能做的选择,而不是沉浸于已经过去的失落。这成为了后来我的一条行事原则。
再后来,第一次出优敏思的差,去新疆做阮行止的 OI 助教。体验了一把新疆的生活,也是很开心的。菜好吃,学校有钱,Wahacer 好玩,阮行止牛逼,以及报销了的饭钱和机票,真的很棒。当然这里还是有一点私心,不过希望以后也能像阮行止这样熟练,我喜欢分享我所拥有的事物,尤其是知识,我希望可以带给更多人知识和乐趣,也尽力以更好的方式分享知识。
暑假的主旋律是搞事情和玩,其中玩也算搞事情的一种吧。总之有了非常多的“第一次”体验,最后体验到了很多不寻常的事情,感谢这个故事里的所有人,至少让我留下了这么多快乐的回忆。
“大学”是什么?这个问题听过北大招生组的老师讲解过一回,后来又听思修老师讲解过。现在来说,大学是学术科研与教学一体的学术机构,其重要性使我们在过去的 18 年里一直为了这个目标而做出相应的努力——是真的吗?
我不觉得。在过去的 18 年里,最后的几年我有了更强的掌握自己的人生的能力,我决心让我自己过得不一样,这才有了学习程序设计、写 Mod、学 OI……这些不同寻常的经历。而就结果来说,这些经历有的与高考并无关联,有的甚至可能会成为考大学的阻碍,但我依然不后悔,甚至可以说非常幸运能有这些经历。当然啦,如何看待自己的人生,这是我上了大学数月之后,在 12 月才仔细思考过的事情,至于前面这些经历,或许只是当时的一时冲动、一厢情愿而已。
总之我最终来了 HUST,上了大学,成为了大学生。但我光知道“大学”是什么,却不知道大学生意味着什么。进入校园之后,我开始探索后面这个问题的答案。
军事训练,简称军训。大学的军训完全不同于高中那种浑水摸鱼的感觉,确实有点东西,有点累。不过其实质逃不过形式,教官都是一些好人,能饶人处且饶人。因此总的来说,军训并不是很累,反而让我有机会接触到其他班上的人,接触到三位很棒的教官。教官因为各种原因决心成为军人,成为祖国安定与和平的卫士,我尊重和支持所有的军人。后来分别与两位海工大教官及其他同学聚餐,很开心。
军训的二十几天其实是空虚的,因为并没有在学习或创造些什么。慢慢地课也陆续开起来了,最开始我还是准点睡觉起床的好学生,上课也基本前排。后来也是受各种人、环境和自己的影响吧,翘课、不听之类的时间也越来越多了。当然,念 ppt 的老师的课翘了是没什么所谓,微积分课不听其实还是有些愧疚的。一个学期下来,心里大概有了一个什么课该翘/不听而什么课有必要上一下/听一下的标准。这算是我认识到“大学生”的第一步吧。
参加了冰岩作坊的秋招,经过笔试面试实习和终面,最后成为了程序组的一名新人,当然还有同届的 zcy、xxh、xww 三位同学/学长。说起来认识 zcy 还是个巧合,当时在优敏思的内部群就聊起来了,还说如果我上了网安可以约寝室,就这么慢慢地熟了,现在还经常到 zcy 寝室去玩,zcy 和他的室友 pg、ysc、yh 都是很棒的人。回到冰岩,认识了形形色色的大佬,程序组就包括 lyt(之前就认识啦)、wj、sfy、zn 四位学长。wj 给我们出了新人任务以及提供指导,后来专门谈了一次心,告诉我要多和身边的厉害的人交流;多反思自己;考试与成绩是有技巧解决的,所以不用浪费时间在收益不大的地方(巨佬学长言论,仅供参考,当然是存在水课的考试能水过去的)……等等,这些建议在之后我都逐步接受并付诸行动了,到目前为止的感觉还不错,感谢各位学长的帮助了。这算是我认识到“大学生”的第二步。当然一个学期的新人任务也让我认识了 HTTP 和 HTTP 服务器的开发(Go 语言 + gin + MongoDB),这是技术上的学习成果。
回到结果论的讨论里。军训后去考了实验班选拔考试(启明考试),无压力过了电信卓越班的笔试,面试甚至被老师称赞了,于是就这么进了信卓。回想起来,好在高中的一段时间跟着老师接触了一些一般水平之上的内容,才能通过考试。后来又过了托福班的考试,不过由于课表冲突没去。好在开课前就转了专业,电信的课比光电少多了,自由时间多了一些,才有办法做冰岩或者自己的事情。就结果来看,虽然没去成 CS 或者网安,但考进了信卓,和一些厉害的人同一个班,随机选择的寝室又分到了神仙学习人舍友,又认识了 zcy 这样很强的同学和 wj 这样能谈心的学长,这都是很好的结果。因此,那时无聊的自信或者自尊是毫无意义的,就算未能达成,命运的安排也不会差。我相信未来一定更好,因此,只需要看清现在,在现在能选择的选项中权衡即可。
关于人生的思考,是在 wj 学长问我“你觉得你读研是为了什么”这个问题开始的。我只知道在实验班保研率为是 40%,这很香,而我想使用这个优惠。至于为什么,这个问题我确实没有思考过,也没能力思考——我甚至不知道我现在的专业可以做些什么。在仔细思考之前,我的观点是,眼界不必局限于加权这一单一的数字,也不必纠结于一时的得失高低,只要有想做的事情,认准了去做就好;如果现实不允许立即做相关的事情,也不必太懊悔,你心中有了目标,妥协一下现实再转而追求也无妨。但最终,我自己也没有明确的目标,或者说我动摇了。我想从事和(亚)文化(可以理解为泛 ACGN)相关的技术工作,由于之前有接触游戏的机会,游戏相关开发工作时我的首选。又由于目前希望读研,工作的事情大概需要先放一放,转而关注学术研究上的事情,最后一份游戏开发的工作可能会显得“屈就”了我。所以到底如何选择呢,目前,我在加权和开发都保有一定的进展,还是放在之后再说吧。学长说我在做无意义的操心,以后自然就会有答案的。确实,不妨先放下这个问题吧。这样的烦恼也是我认识“大学生”的一个方面。
虽然大学不是第一次让我有机会掌握自己的人生,但确是第一次让我有机会规划自己的财务,其结果,反正不是很好。由于爱吃喝的天性,我的饮食支出总是贴着上限;又由于买了一些必须品或不必须但想要的东西,加起来总是会超出最开始商量好的预算。自己的控制力真的很有限,控制到顿顿吃学一就能控制饮食开销了,却无法做到,大概我确实没什么自控的能力吧。但之后会努力更小心地对待自己的账目,攒起钱做未来的“第一次”基金。此外,还广泛了解了信用产品的相关知识,用了若干次花呗和京东白条,又申请了 VISA 的信用卡(0 额度),有了许多金融的经验。掌握钱也是“大学生”的生活日常与任务之一呢。
有幸联系上了郑老师,成为了原 NOIP 现 CSP 竞赛的志愿者,留下了一些特别的体验感受。从接受测试的选手转变为帮助选手享受更好的测试环境的幕后人员,是很有意思的转变。不过最大的体验是,从后辈的身上看到了当年自己的影子,那种不服与失落完全就是我当时的复制,但是我所做出的选择需要巨大的投入与牺牲,已经可以称得上是下注巨大的赌博,真的不推荐这样的做法。因此只能从 1 年后的我这一角度和他交流,分享我自己 1 年来的感受与变化。能帮到其他人排解内心的痛苦,能回到熟悉的考场,让竞赛变得更好,这一切都使我开心。CSP 的游记也写了,可以看这里。
现在是考试周,其实考试的体验并不好,也怪我这个学期后边的课并不是很认真对待,或者说学习的效率低下还没投入时间。看到大家都在写年终总结,感觉过去的 1 年里也发生了很多事,自己改变了许多,于是开了这个坑。对我自己来说,最大的影响或者感受大概是,初步认识到了“大学生”意味着什么。自己已经是一个 18 岁的人了,也被赋予了管理自己的一切的自由,那么就需要细心的经营来承担起自由的责任。毕竟,人生是自己的,万万不可瞎搞。
在过去的 1 年里,创造出的这么多个故事里,所有相关的人或事都是我应该感谢的,我很幸运可以与大家创造出这些美好的回忆。也希望未来真的如我相信的那样变得更好,道路也明确起来,自己也变得更像一个大学生。更重要的是,在迷茫的时候能够摸清内心的真实想法,而不是向奇怪的势力妥协,落下一个遗憾。
已经这么晚了呢,各位新年快乐,晚安。
KSkun
2020 年 1 月 1 日
![[CSP-J2 2019]纪念品 题解](https://ksmeow.moe/wp-content/uploads/2019/11/shirobako2-2.jpg)
题目地址:洛谷:P5662 纪念品 – 洛谷 | 计算机科学教育新生态
小伟突然获得一种超能力,他知道未来 $T$ 天 $N$ 种纪念品每天的价格。某个纪念品的价格是指购买一个该纪念品所需的金币数量,以及卖出一个该纪念品换回的金币数量。
每天,小伟可以进行以下两种交易无限次:
每天卖出纪念品换回的金币可以立即用于购买纪念品,当日购买的纪念品也可以当日卖出换回金币。当然,一直持有纪念品也是可以的。
$T$ 天之后,小伟的超能力消失。因此他一定会在第 $T$ 天卖出所有纪念品换回金币。
小伟现在有 $M$ 枚金币,他想要在超能力消失后拥有尽可能多的金币。
有 $N$ 种纪念品,给出 $T$ 天内每种纪念品的价格,每天可以以当日价格买和卖纪念品,初始时有 $M$ 钱,求买卖方案使最终钱数最大。
输入格式:
第一行包含三个正整数 $T, N, M$,相邻两数之间以一个空格分开,分别代表未来天数 $T$,纪念品数量 $N$,小伟现在拥有的金币数量 $M$。
接下来 $T$ 行,每行包含 $N$ 个正整数,相邻两数之间以一个空格分隔。第 $i$ 行的 $N$ 个正整数分别为 $P_{i,1}$,$P_{i,2}$,……,$P_{i,N}$,其中 $P_{i,j}$ 表示第 $i$ 天第 $j$ 种纪念品的价格。
输出格式:
输出仅一行,包含一个正整数,表示小伟在超能力消失后最多能拥有的金币数量。
输入样例 #1:
6 1 100 50 20 25 20 25 50
输出样例 #1:
305
输入样例 #2:
3 3 100 10 20 15 15 17 13 15 25 16
输出样例 #2:
217
对于 $10\%$ 的数据,$T = 1$。
对于 $30\%$ 的数据,$T \leq 4, N \leq 4, M \leq 100$,所有价格 $10 \leq P_{i,j} \leq 100$。
另有 $15\%$ 的数据,$T \leq 100, N = 1$。
另有 $15\%$ 的数据,$T = 2, N \leq 100$。
对于 $100\%$ 的数据,$T \leq 100, N \leq 100, M \leq 10^3$,所有价格 $1 \leq P_{i,j} \leq 10^4$,数据保证任意时刻,小明手上的金币数不可能超过 $10^4$。
既然同一天的买和卖是可以任意进行的,则持有的一个纪念品在某一天不参与买卖,等价于某一天卖了一个纪念品又买了一个。因此,在某一天买纪念品之前可以先把持有的纪念品全都卖掉,然后再决定如何买纪念品。
有了上述对模型的简化后,容易设计出 DP 状态为 $f(i, j, k)$ 表示第 $i$ 天时,考虑第 $j$ 个纪念品,手上还剩 $k$ 钱时后一天卖出后得到的最多钱数,容易获得以下转移:
$$ f(i, j, k) = \max \{ f(i, j-1, k+P_{i, j}) – P_{i, j} + P_{i+1, j} \} $$
DP 的初始值为该天不进行买卖, $ f(i, j, k) = k $。
接下来对上述模型进行优化。首先发现转移与第一维没关系,直接删去也不会影响正确性。然后转移的第二维只与比 $j$ 小的状态相关,因此用逆序转移(类似完全背包的转移)可以保证正确性,第二维也同样可以删去。最终的 DP 状态只保留了一维。
当开始计算第 $i+1$ 天时,这一天的初始钱数为前一天的最大钱数 $m$ ,因此直接令 $f(m)=m$ (这一天不买纪念品,钱数不发生变化)作为 DP 初始值即可。其他状态的初始值应设为极小值 $0$ 。
令 $C = 10^4$ 表示可能的最大钱数,则该算法的复杂度为 $O(N^2C)$ 。
// Code by KSkun, 2019/11
#include <cstdio>
#include <cctype>
#include <cstring>
#include <algorithm>
#include <utility>
typedef long long LL;
typedef std::pair<int, int> PII;
inline char fgc() {
static char buf[100000], * p1 = buf, * p2 = buf;
return p1 == p2 && (p2 = (p1 = buf) + fread(buf, 1, 100000, stdin), p1 == p2)
? EOF : *p1++;
}
inline LL readint() {
LL res = 0, neg = 1; char c = fgc();
for(; !isdigit(c); c = fgc()) if(c == '-') neg = -1;
for(; isdigit(c); c = fgc()) res = res * 10 + c - '0';
return res * neg;
}
inline char readsingle() {
char c;
while(!isgraph(c = fgc())) {}
return c;
}
const int MAXN = 105;
int t, n, m, p[MAXN][MAXN], f[10005];
int main() {
t = readint(); n = readint(); m = readint();
for (int i = 1; i <= t; i++) {
for (int j = 1; j <= n; j++) {
p[i][j] = readint();
}
}
int ans = m;
for (int i = 1; i <= t; i++) {
memset(f, 0, sizeof(f));
f[ans] = ans;
for (int j = 1; j <= n; j++) {
for (int k = ans; k >= p[i][j]; k--) {
f[k - p[i][j]] = std::max(f[k - p[i][j]], f[k] - p[i][j] + p[i + 1][j]);
}
}
int mx = 0;
for (int i = 0; i <= ans; i++) {
mx = std::max(mx, f[i]);
}
ans = mx;
}
printf("%d", ans);
return 0;
}Copyright © 2017-2022 KSkun's Blog.
Authored by KSkun and his friends.

本博客内所有原创内容采用知识共享署名-相同方式共享 4.0 国际许可协议进行许可。引用内容如果侵权,请在此留言。
All original content in this blog is licensed under a Creative Commons Attribution-ShareAlike 4.0 International License.
If any reference content infringes your rights, please contact us.



![[CSP-S2 2019]划分 题解](https://ksmeow.moe/wp-content/uploads/2019/12/shirobako2-4-760x400.jpg)
![[CSP-S2 2019]Emiya 家今天的饭 题解](https://ksmeow.moe/wp-content/uploads/2019/12/shirobako2-3-760x400.jpg)
![[CSP-J2 2019]加工零件 题解](https://ksmeow.moe/wp-content/uploads/2019/11/shirobako2-1-760x400.jpg)