![[NOIP2013提高]货车运输 题解](https://ksmeow.moe/wp-content/uploads/2018/05/180430d-591x400.jpg)
[NOIP2013提高]货车运输 题解
题目地址:洛谷:【P1967】货车运输 – 洛谷 题目描述 A 国有 n 座城 …
May all the beauty be blessed.
![[洛谷1726]上白泽慧音 题解](https://ksmeow.moe/wp-content/uploads/2018/04/180430b.jpg)
题目地址:洛谷:【P1726】上白泽慧音 – 洛谷
在幻想乡,上白泽慧音是以知识渊博闻名的老师。春雪异变导致人间之里的很多道路都被大雪堵塞,使有的学生不能顺利地到达慧音所在的村庄。因此慧音决定换一个能够聚集最多人数的村庄作为新的教学地点。人间之里由N个村庄(编号为1..N)和M条道路组成,道路分为两种一种为单向通行的,一种为双向通行的,分别用1和2来标记。如果存在由村庄A到达村庄B的通路,那么我们认为可以从村庄A到达村庄B,记为(A,B)。当(A,B)和(B,A)同时满足时,我们认为A,B是绝对连通的,记为<A,B>。绝对连通区域是指一个村庄的集合,在这个集合中任意两个村庄X,Y都满足<X,Y>。现在你的任务是,找出最大的绝对连通区域,并将这个绝对连通区域的村庄按编号依次输出。若存在两个最大的,输出字典序最小的,比如当存在1,3,4和2,5,6这两个最大连通区域时,输出的是1,3,4。
输入格式:
第1行:两个正整数N,M
第2..M+1行:每行三个正整数a,b,t, t = 1表示存在从村庄a到b的单向道路,t = 2表示村庄a,b之间存在双向通行的道路。保证每条道路只出现一次。
输出格式:
第1行: 1个整数,表示最大的绝对连通区域包含的村庄个数。
第2行:若干个整数,依次输出最大的绝对连通区域所包含的村庄编号。
输入样例#1:
5 5 1 2 1 1 3 2 2 4 2 5 1 2 3 5 1
输出样例#1:
3 1 3 5
对于60%的数据:N <= 200且M <= 10,000
对于100%的数据:N <= 5,000且M <= 50,000
复习一下Tarjan强连通分量算法。是裸的找最大强连通分量的题。
// Code by KSkun, 2018/4
#include <cstdio>
#include <cmath>
#include <cctype>
#include <vector>
#include <set>
#include <stack>
#include <algorithm>
typedef long long LL;
inline char fgc() {
static char buf[100000], *p1 = buf, *p2 = buf;
return p1 == p2 && (p2 = (p1 = buf) + fread(buf, 1, 100000, stdin), p1 == p2) ? EOF : *p1++;
}
inline LL readint() {
register LL res = 0, neg = 1;
register char c = fgc();
while(!isdigit(c)) {
if(c == '-') neg = -1;
c = fgc();
}
while(isdigit(c)) {
res = (res << 1) + (res << 3) + c - '0';
c = fgc();
}
return res * neg;
}
const int MAXN = 10005;
std::vector<int> gra[MAXN];
int n, m;
int dfn[MAXN], low[MAXN], clk;
std::set<int> scc;
int sno[MAXN], ssiz[MAXN], scnt;
bool insta[MAXN];
std::stack<int> sta;
inline void tarjan(int u) {
dfn[u] = low[u] = clk++;
sta.push(u); insta[u] = true;
for(int v : gra[u]) {
if(!dfn[v]) {
tarjan(v);
low[u] = std::min(low[u], low[v]);
} else if(insta[v]) {
low[u] = std::min(low[u], dfn[v]);
}
}
if(dfn[u] == low[u]) {
scnt++;
int p;
do {
p = sta.top(); sta.pop();
sno[p] = scnt;
ssiz[scnt]++;
insta[p] = false;
} while(p != u);
if(scc.empty() || ssiz[scnt] > ssiz[*scc.begin()]) {
scc.clear(); scc.insert(scnt);
} else if(ssiz[scnt] == ssiz[*scc.begin()]) {
scc.insert(scnt);
}
}
}
int a, b, t;
int main() {
n = readint(); m = readint();
while(m--) {
a = readint(); b = readint(); t = readint();
gra[a].push_back(b);
if(t == 2) gra[b].push_back(a);
}
for(int i = 1; i <= n; i++) {
if(!dfn[i]) tarjan(i);
}
printf("%d\n", ssiz[*scc.begin()]);
int tar = 0;
for(int i = 1; i <= n; i++) {
if(!tar && scc.count(sno[i])) tar = sno[i];
if(sno[i] == tar) printf("%d ", i);
}
return 0;
}
![[SCOI2005]扫雷 题解](https://ksmeow.moe/wp-content/uploads/2018/04/180429c.jpg)
题目地址:洛谷:【P2327】[SCOI2005]扫雷 – 洛谷、BZOJ:Problem 1088. — [SCOI2005]扫雷Mine
相信大家都玩过扫雷的游戏。那是在一个 n×m 的矩阵里面有一些雷,要你根据一些信息找出雷来。万圣节到了,“余”人国流行起了一种简单的扫雷游戏,这个游戏规则和扫雷一样,如果某个格子没有雷,那么它里面的数字表示和它8连通的格子里面雷的数目。现在棋盘是 n×2 的,第一列里面某些格子是雷,而第二列没有雷,如下图:
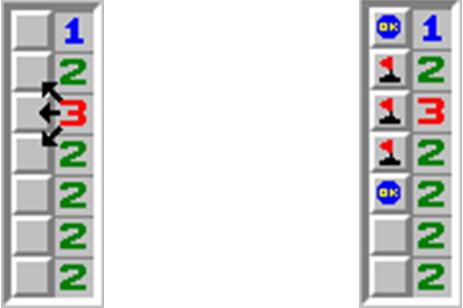
由于第一列的雷可能有多种方案满足第二列的数的限制,你的任务即根据第二列的信息确定第一列雷有多少种摆放方案。
输入格式:
第一行为N,第二行有N个数,依次为第二列的格子中的数。(1<= N <= 10000)
输出格式:
一个数,即第一列中雷的摆放方案数。
输入样例#1:
2 1 1
输出样例#1:
2
这道题的解法很多很多,我最开始的想法是存6位状压递推[eq]O(n)[/eq]解,然后特判[eq]n \leq 6[/eq]的情况。
实际上我们发现只需要枚举第一位有没有雷,剩下的位置都唯一确定了,因为一个位置有没有雷可以通过上个位置的数值减去上个位置和上上个位置的雷数得到。也就是说,方案数不会超过2,因此我们枚举第一个位置有没有雷,通过模拟计算下面的情况,如果这个位置要求的雷数非0或1则方案失败。每模拟成功一次计算一个方案。注意模拟的时候要判断末尾是否满足,可以多填一位,再判断n+1位是否有雷多出来了。模拟的复杂度也是[eq]O(n)[/eq]的。
// Code by KSkun, 2018/4
#include <cstdio>
#include <cctype>
#include <cstring>
#include <algorithm>
typedef long long LL;
inline char fgc() {
static char buf[100000], *p1 = buf, *p2 = buf;
return p1 == p2 && (p2 = (p1 = buf) + fread(buf, 1, 100000, stdin), p1 == p2) ? EOF : *p1++;
}
inline LL readint() {
register LL res = 0, neg = 1;
register char c = fgc();
while(!isdigit(c)) {
if(c == '-') neg = -1;
c = fgc();
}
while(isdigit(c)) {
res = (res << 1) + (res << 3) + c - '0';
c = fgc();
}
return res * neg;
}
const int MAXN = 10005;
int n, a[MAXN], has[MAXN];
inline bool cal() {
for(int i = 2; i <= n + 1; i++) {
has[i] = a[i - 1] - has[i - 1] - has[i - 2];
if(has[i] != 0 && has[i] != 1) return false;
if(i == n + 1 && has[i] != 0) return false;
}
return true;
}
int main() {
n = readint();
for(int i = 1; i <= n; i++) {
a[i] = readint();
}
int ans = 0;
if(cal()) ans++;
memset(has, 0, sizeof(has));
has[1] = 1;
if(cal()) ans++;
printf("%d", ans);
return 0;
}
![[JLOI2013]卡牌游戏 题解](https://ksmeow.moe/wp-content/uploads/2018/04/180428a.jpg)
题目地址:洛谷:【P2059】[JLOI2013]卡牌游戏 – 洛谷、BZOJ:Problem 3191. — [JLOI2013]卡牌游戏
N个人坐成一圈玩游戏。一开始我们把所有玩家按顺时针从1到N编号。首先第一回合是玩家1作为庄家。每个回合庄家都会随机(即按相等的概率)从卡牌堆里选择一张卡片,假设卡片上的数字为X,则庄家首先把卡片上的数字向所有玩家展示,然后按顺时针从庄家位置数第X个人将被处决即退出游戏。然后卡片将会被放回卡牌堆里并重新洗牌。被处决的人按顺时针的下一个人将会作为下一轮的庄家。那么经过N-1轮后最后只会剩下一个人,即为本次游戏的胜者。现在你预先知道了总共有M张卡片,也知道每张卡片上的数字。现在你需要确定每个玩家胜出的概率。
这里有一个简单的例子:
例如一共有4个玩家,有四张卡片分别写着3,4,5,6.
第一回合,庄家是玩家1,假设他选择了一张写着数字5的卡片。那么按顺时针数1,2,3,4,1,最后玩家1被踢出游戏。
第二回合,庄家就是玩家1的下一个人,即玩家2.假设玩家2这次选择了一张数字6,那么2,3,4,2,3,4,玩家4被踢出游戏。
第三回合,玩家2再一次成为庄家。如果这一次玩家2再次选了6,则玩家3被踢出游戏,最后的胜者就是玩家2.
输入格式:
第一行包括两个整数N,M分别表示玩家个数和卡牌总数。
接下来一行是包含M个整数,分别给出每张卡片上写的数字。
输出格式:
输出一行包含N个百分比形式给出的实数,四舍五入到两位小数。分别给出从玩家1到玩家N的胜出概率,每个概率之间用空格隔开,最后不要有空格。
输入样例#1:
5 5 2 3 5 7 11
输出样例#1:
22.72% 17.12% 15.36% 25.44% 19.36%
输入样例#2:
4 4 3 4 5 6
输出样例#2:
25.00% 25.00% 25.00% 25.00%
对于30%的数据,有1<=N<=10
对于50%的数据,有1<=N<=30
对于100%的数据,有1<=N<=50 1<=M<=50 1<=每张卡片上的数字<=50
10%自然就是爆搜乱搞了。50%实话说没想到。
看上去算法是[eq]O(n^3)[/eq]的。我们需要注意到一点,即淘汰的操作仅关心被淘汰人与庄家的相对位置关系,记录这个相对位置关系就好办了。且这个游戏每次只淘汰一人,即总是从剩i人向剩i-1人发展。设计状态dp[i][j]表示剩下i人从庄家开始顺时针数j人这个人胜出的概率,我们考虑随机从当前局面淘汰一人,只需要知道淘汰并且重新选定庄家后现在这个人在下一个局面的什么位置即可,即转移是
\displaystyle dp[i][j] = \sum \frac{dp[i-1][j']}{m}
还剩一人时这个人就胜出了,因此dp[1][1]=1。由于初始的时候1做庄家,答案就是dp[n][1]~dp[n][n]。
// Code by KSkun, 2018/4
#include <cstdio>
#include <cctype>
#include <cstring>
typedef long long LL;
inline char fgc() {
static char buf[100000], *p1 = buf, *p2 = buf;
return p1 == p2 && (p2 = (p1 = buf) + fread(buf, 1, 100000, stdin), p1 == p2) ? EOF : *p1++;
}
inline LL readint() {
register LL res = 0, neg = 1;
register char c = fgc();
while(!isdigit(c)) {
if(c == '-') neg = -1;
c = fgc();
}
while(isdigit(c)) {
res = (res << 1) + (res << 3) + c - '0';
c = fgc();
}
return res * neg;
}
const int MAXN = 55;
int n, m, a[MAXN];
double dp[MAXN][MAXN];
int main() {
n = readint(); m = readint();
for(int i = 1; i <= m; i++) {
a[i] = readint();
}
dp[1][1] = 1;
for(int i = 2; i <= n; i++) {
for(int j = 1; j <= i; j++) {
for(int k = 1; k <= m; k++) {
int nxt = a[k] % i;
if(!nxt) nxt = i;
if(nxt > j) dp[i][j] += dp[i - 1][i - nxt + j] / m;
else if(nxt < j) dp[i][j] += dp[i - 1][j - nxt] / m;
}
}
}
for(int i = 1; i <= n; i++) {
printf("%.2lf%% ", dp[n][i] * 100);
}
return 0;
}
Copyright © 2017-2022 KSkun's Blog.
Authored by KSkun and his friends.

本博客内所有原创内容采用知识共享署名-相同方式共享 4.0 国际许可协议进行许可。引用内容如果侵权,请在此留言。
All original content in this blog is licensed under a Creative Commons Attribution-ShareAlike 4.0 International License.
If any reference content infringes your rights, please contact us.
![[SDOI2009]Elaxia的路线 题解](https://ksmeow.moe/wp-content/uploads/2018/04/180430c.jpg)
![[洛谷1993]小K的农场 题解](https://ksmeow.moe/wp-content/uploads/2018/04/180430a-544x400.jpg)
![[NOIP2006提高]2^k进制数 题解](https://ksmeow.moe/wp-content/uploads/2018/04/180429d-747x400.jpg)
![[CQOI2007]余数求和 题解](https://ksmeow.moe/wp-content/uploads/2018/04/180429b-615x400.jpg)
![[SDOI2009]虔诚的墓主人 题解](https://ksmeow.moe/wp-content/uploads/2018/04/180429a-224x400.jpg)
![[SCOI2010]生成字符串 题解](https://ksmeow.moe/wp-content/uploads/2018/04/180427d.jpg)