NTP 网络时间协议

By KSkun, 2020/7/20
NTP(Network Time Procotol,网络时间协议)是今天仍在使用的最古老的互联网协议之一。它从 1985 年首次被实现以来,已经为互联网中的无数台设备提供了时间校准的服务,成为了大部分依赖于准确时间的应用得以实现的基础。本文中,我们将简要介绍 NTP 的一个参考实现,以在读者的心中建立 NTP 协议的原理框架。
NTP 是什么
NTP 是一种通过网络在计算机之间进行时钟同步的协议,它工作在 OSI 模型的应用层,通过一系列原理与算法,实现以极小的误差,将所有网络中的计算机与 UTC 同步。
由于时钟硬件精度的限制,离线的设备不总是能时刻与 UTC 同步,误差随着时间累积使计算机的本地时钟产生较大的偏差。此外,设备初次启动,启动前时钟仍处于默认状态,也需要与现在的时间同步。因此,通过互联网与可靠的时间源同步是必要的。通过这一协议,设备将寻找合适的同步源,将自身时钟与同步源同步,以保证依赖时间的应用能正常运行。
在你的手机、电脑等设备上都可以找到使用 NTP 同步时钟的设置:
NTP 的网络结构
在 NTP 中,计算机之间的关系形如下图中的分层系统:

在这个系统中,层次被称为 stratum。如图所示,提供精确时间的时间源被认为在第 0 层(Stratum 0),它们与第 1 层的计算机(称为主要服务器)直接相连(表示为黄色箭头),而在下面的层中,既存在与上一层的同步,也存在层次内部的同步,它们都是通过网络连接进行的(表示为红色箭头)。
NTP 的层次最多可存在 15 层,第 16 层用于表示该设备未同步。通过一系列时间源的选择算法,可以确保上述结构形成了某种最优的生成树结构,使得每台计算机到第 1 层的路径都是最优路径。
NTP 中的时间与数据格式
NTP 的数据格式

如图所示,NTP 定义了两种数据格式:时间戳(timestamp)和日期戳(datestamp)。它们分别提供不同范围的时间表示法。
时间戳长 64 位,前 32 位表示从时代起点(era epoch,目前起点为 1900/1/1 00:00:00)开始的秒数,后 32 位表示秒数的小数部分。这样的时间表示具有 232 皮秒(即 232×10-12 秒)的精度。但这种表示法只能表示有限范围内的时间,因此时间戳存在一个 136 年的周期,一个周期称为一个 NTP 的时代(era)。下一个时代的起点在 2036 年。
日期戳长 128 位,前 32 位表示时代编号(从 0 开始),后 96 位是一个时间戳,分别为 32 位的秒数和 64 位的小数部分。容易发现,日期戳能表示的时间范围更广,精度也更高,它的跨度长于宇宙的年龄,精度小于光通过一个原子的时间。
时间戳常用于通信时的数据包中,而日期戳一般只在实现内部使用。
NTP 时间与 Unix 时间
NTP 标度与 Unix 标度只相差一个常数 2208988800,这是 1900/1/1 (NTP 标度起点)与 1970/1/1 (Unix 标度起点)之间的秒数差别。
NTP 的闰秒处理
广泛使用的时间是协调世界时间(UTC),但基于原子钟中原子的震荡计算的国际原子时(TAI)会因为地球自转的不规则变化与 UTC 产生差别。当差别过大时,我们通过+1s插入闰秒(leap second)的方式修正这种差别。
NTP 的时间基于 UTC,因此需要特殊处理插入闰秒的情形。为了满足时间的连续性和单调性,以及需要保证时间戳与现实时间的对应关系不改变,NTP 采用的方式是在闰秒时冻结时钟的增加。
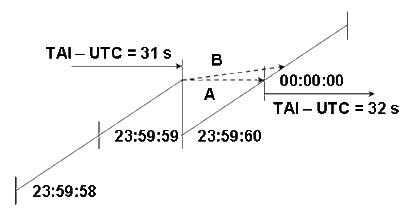
如上图所示,闰秒插入在 23:59:59 之后,在进入闰秒时精确冻结时钟一秒,闰秒结束后再释放时钟。
从 1972 年以来插入的闰秒时间可以在文件 leap-seconds.list(https://www.ietf.org/timezones/data/leap-seconds.list)中找到,通过这些信息可以计算 TAI 与 UTC 的差别,进而进行换算。
NTP 时间戳的运算
NTP 时间戳只支持作差运算,由于 NTP 时间戳的本质是定长小数,差运算可以看成是对 2 的整数次幂取模意义下的运算。因此,只要两个时间戳之间的间隔不超过 68 年(时间戳周期的一半),作差的结果就是正确的。
时间戳运算在协议中的应用会在之后的算法中具体介绍。
NTP 的架构与算法
NTP 的架构
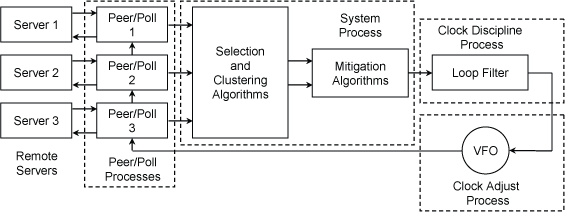
上图展示了 NTP 协议的架构,我们将分别具体介绍每一部分的内容。
NTP 数据包结构

NTP 通过 UDP 传输数据,上图是一个 NTP 的数据包结构,各字段的含义分别如下:
- 闰秒指示(LI,Leap Indicator):提示是否存在需要处理的闰秒;
- 版本号(VN,Version):NTP 的版本号,目前为 4;
- 模式(Mode):表明通信模式,如对等端、客户端、服务端、广播等。
- 层次(Stratum):所在层次数;
- 轮询间隔(Poll);
- 精度(Precision):系统时钟精度;
- 根延迟(Root Delay):到参考时钟的往返延迟;
- 根分散度(Root Dispersion):到参考时钟的总采样分散程度,反应采样值的错误情况;
- 参考 ID(Reference ID):对于层次为 0 的包,该字段用于表示控制包的控制指令;对于层次为 1 的包,该字段代表了参考时钟的类型,如来自卫星定位系统时钟、射频时钟等;
- 参考时间戳(Reference Timestamp):系统时钟最近一次校准的时间;
- 源时间戳(Origin Timestamp,org):请求离开客户端的时间;
- 接收时间戳(Receive Timestamp,rec):请求被服务器接收的时间;
- 传输时间戳(Transmit Timestamp,xmt):响应离开服务器的时间;
- 到达时间戳(Destination Timestamp,dst):响应到达客户端的时间,该字段不在数据包中;
- 扩展域(Extension Field);
- 密钥 ID(Key Identifier):用于客户端和服务器生成一个 128 位的 MD5 密钥;
- 消息摘要(Message Digest):通过密钥生成的 128 位 MD5 哈希值。
时间同步的计算方法

如图所示,一次 NTP 通信(C/S 模式下)由客户端先发起一个请求,再由服务器响应,这个过程中总共会记录四个时间戳:发出请求的时间戳 T1(图中 t0)、接收请求的时间戳 T2(图中 t1)、发出响应的时间戳 T3(图中 t2)、接收响应的时间戳 T4(图中 t3)。其中,T1、T4 在客户端测量,因此使用客户端时钟,而 T2、T3 使用服务器时钟。
如果我们直接计算差值 T2 – T1,得到的是服务器相对客户端的时钟偏差与网络传输时间之和,而 T3 – T4 恰好是这两者之差,因此时钟偏差可以由下式计算得出。
offset = [ (T2 – T1) + (T3 – T4) ] / 2
此外,我们需要获得客户端到服务器的往返延迟,容易通过下式计算。
delay = (T4 – T1) – (T3 – T2)
NTP 有线协议(NTP On-Wire Protocols)
NTP 有线协议通过一系列规则,确保了计算机与时间源同步时数据的可靠性与准确性,作为架构中支撑轮询环节的组成部分存在。
软件戳和硬件戳
在一次 NTP 的交互中,客户端和服务端各自需要记录两个时间戳。其中,接收时间戳可以在网络接口收到该数据包时在硬件层被记录,但发送时间戳只能在将数据包交给网络接口发送前记录。前者由于在硬件处被记录,被称为硬件戳(drivestamp),而后者被称为软件戳(softstamp)。利用软件戳计算延迟是不准确的,因为记录软件戳后,还要经过计算消息摘要、排队发送等过程,与数据包离开计算机的时间存在一定误差。
在下面的内容中,带 * 号的时间戳是软件戳,否则为硬件戳。
基本对称模式(Basic Symmetric Mode)
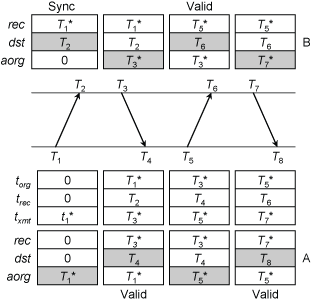
在基本对称模式下,每一端运行一个状态机,并有状态变量 rec、dst、aorg。当数据包到达时,将数据包 txmt 复制到 rec,并将接收时间戳记录到 dst。当数据包离开时,将 rec 复制到 torg,dst 复制到 trec,并将发送时间戳记录到 org 和 txmt。
当数据包完成一个往返后,客户端一方收到的数据包中已经包含了 T1、T2、T3 三个时间戳,同时硬件提供了 T4 时间戳,便可通过上面的原理计算该服务器的偏差与延迟。
此外,客户端会将请求发出的时间 T1 记录在 aorg 中,如果收到的数据包 torg 与 aorg 不相同,则数据包不属于当前回合,将被丢弃。
此模式下,发送时间戳都为软件戳,因此存在一定的误差。
交错对称模式(Interleaved Symmetric Mode)
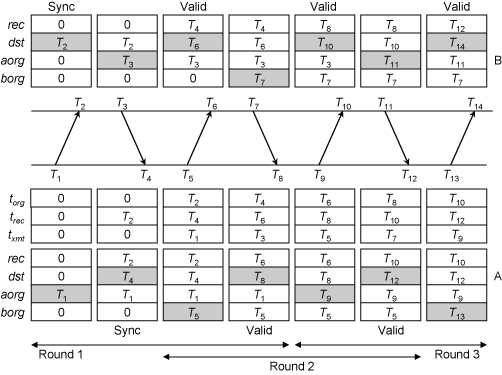
为了解决基本对称模式中,发送时间戳为软件戳的误差问题,产生了交错对称模式。该模式下,所有时间戳都为硬件戳,其中,发送时间戳是在数据包离开后被记录的。
在该模式下,完成一次偏差与延迟的计算需要两个回合。每一方的状态变量除已经提到的 rec、dst、aorg 外,还增加了 borg,以及图中未展示的 xmt(用于进行检查)、x(只有两个值 +1 和 -1,每一回合交换)和 f(用于指示是否已同步)。
当数据包将发出时,将 rec 复制到 torg,dst 复制到 trec。如果此时 x = +1,发送时间戳记录到 aorg,并将 borg 复制到 txmt;如果 x = -1,发送时间戳记录到 borg,并将 aorg 复制到 txmt。收到数据包时,计算式中各值都可以给出:T2 = rec,T3 = txmt,T4 = dst,当 x = +1 时 T1 = aorg,否则 T1 = borg;之后,将 trec 复制到 rec,并且将接收时间戳保存在 dst。
对于客户端来说,一回合的 T1、T4 硬件戳都可以直接获得,T2 硬件戳将在该回合的响应中返回,而 T2 硬件戳在该回合响应发出后才能获得,因此只能放置在下一回合的响应中返回。因此,进行一次偏差与延迟的计算必须有两回合。
此外,当客户端记录的 dst 与响应的 torg 不相同时,该数据包不属于当前回合,因此会被丢弃。
交错广播模式(Interleaved Broadcast Mode)
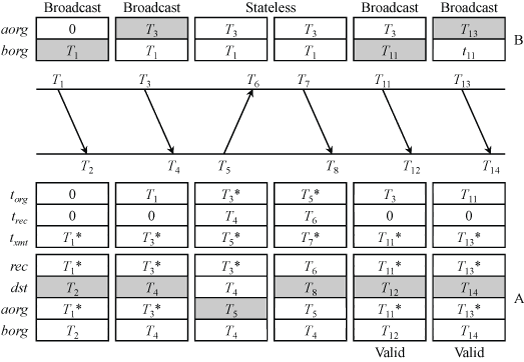
在广播模式下,服务器不会保存来自客户端的信息,因此需要特殊的流程来进行同步。
客户端具有四个状态变量 rec、dst、aorg 和 borg,此外,还有图中未表示的状态变量 b (只有 0 和 1 两个取值)和 d(表示往返延迟)。
客户端会进行一次校准回合,该回合与基本对称模式中的回合相似,收到响应后客户端将 trec 复制到 rec,并将 b 设为 1。接下来,客户端收到第一个广播响应,此时 b = 1,由于这一回合中响应的发送硬件戳无法在这一回合中获取,客户端使用上半回合与上一次的广播响应计算往返延迟。客户端通过 T1 = torg,T2 = borg,T3 = aorg,T4 = rec 计算出往返延迟 d,并将 b 设为 0。之后的广播响应中,客户端通过下式计算偏移。
offset = (torg + d/2) – dst
注意到广播响应每一次都会携带上一次广播响应的发送硬件戳,可以将上一次响应携带的发送软件戳与其对照,其差值为生成消息摘要和排队发送的延迟,如果该延迟小于 0 或大于某阈值,则认为数据包不属于本回合。
错误探测与恢复
当客户端与服务器工作在不同的模式下时往往会出现不能对应的现象。对于每一种模式,其错误探测机制可以检查到模式的不对应,并自动调整模式。
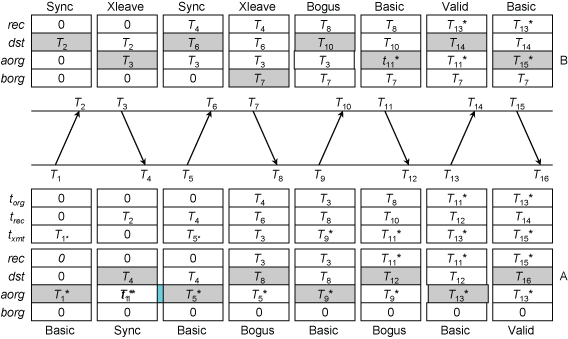
在上图中,A 只能工作在基本对称模式,而 B 最开始工作在交错对称模式。在第三个回合中,B 收到了无效的请求,并发现 torg 与 aorg 相同,则判定 A 工作在基本对称模式,可以立即切换模式进行响应。
时钟筛选与聚类算法
时钟筛选与聚类算法包括时钟过滤算法、时钟选择算法和时钟聚类算法三部分,它们负责从所有时间源中筛选出那些最准确、最可靠的候选时间源,并交给下一步中的平缓算法决定一个时间源作为系统源。
时间过滤算法(Clock Filter Algorithm)
时钟过滤算法从有线协议中计算得到的每个时钟源的多个偏移和延迟中进行初步的筛选。
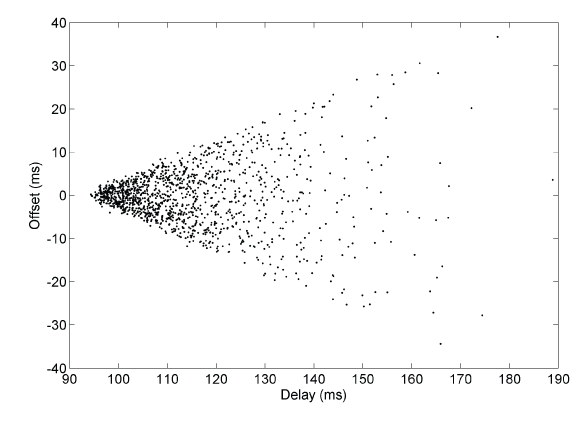
观察上图,容易发现采样数据的边缘近似为两条直线,斜率分别为 ±0.5。随着延迟的增加,偏移量的变化范围也增加了,说明偏移的误差增大。因此,对于一系列数据,我们应当采用延迟最小的样本,因为此时偏移的误差最小。
对于传输大量数据的情况下,网络延迟会显著增加,导致大量采样点分布在边缘附近。
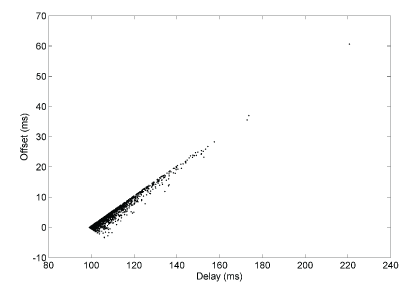
此时,可以应用 Huff-n’-Puff 过滤算法(The Huff-n’-Puff Filter)。在最小延迟 x0 = 100 ms 时,偏移量 y0 = 0。对于边缘附近的点 (x, y),通过下式修正其偏移量。
对于上边缘附近的点 offset = y – (x – x0) / 2
对于下边缘附近的点 offset = y + (x – x0) / 2
但这一过滤算法对分布在边缘以内的数据效果不好,因此仅用于修正网络流量较大时高延迟导致的问题。
经过初步处理后,算法将获取的样本插入一个 8 位的移位寄存器中,寄存器中存储的 8 个样本总是最新的样本,并从中取出延迟最小的一个样本。
此外,算法还计算出该时钟源的源抖动(peer jitter),定义为偏差样本与选出的偏差差值的均方根。
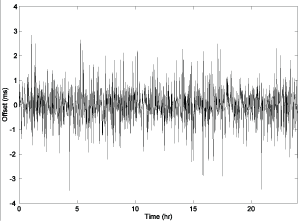
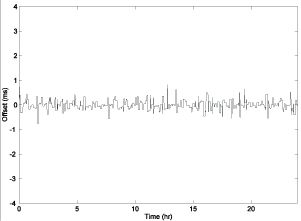
通过筛选前后样本的对比,证实过滤算法有效降低了偏差值的错误。
时钟选择算法(Clock Select Algorithm)
时钟选择算法负责从所有时钟源中排除具有明显错误的源(falseticker),最终给出一系列提供正确数据的源(truechimer)。
首先,算法对所有源进行一次健全性测试(sanity check),测试项目包括:
- 层次错误:当时钟源未同步或不满足配置的最低、最高层次限制;
- 距离错误:当时钟源的根距离(root distance,通过该时钟源到主要服务器的总误差量,为延迟、抖动与分散度之和)超过配置限制;
- 环路错误:当时钟源与本机同步时;
- 不可达错误:当时钟源不可达时。
发生错误的时钟源将不会被选择。
接下来,对于每个时钟源定义它的置信区间(correctness interval)。用 θ0 表示该源的测量偏差,λ 表示根距离,则该源的置信区间为 [θ0 – λ, θ0 + λ]。认为与其他源置信区间没有交集的源为错误的源,例如,下图中 D 与其他三个源的置信区间没有交集,则认为 D 是错误的。
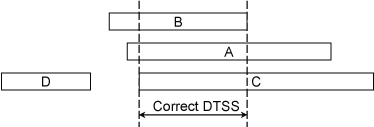
算法通过一个过程选出最多有多少源存在交集,并将这些源作为结果交给下一环节处理。该流程如下图所示。

时钟聚类算法(Clock Cluster Algorithm)
时钟聚类算法对经过两轮筛选后留下的时钟源做进一步处理,排除那些远离偏移量中心的源,经过此次筛选后的源将交给平缓算法进行最终的选择。
假设待处理的时钟源构成数组,对于第 i 个源,其偏移为 θ(i),根距离为 λ(i)。定义一个 j 相对 i 的统计量为 di(j) = |θ(j) – θ(i)| λ(i),对于一个源 i,可以计算出其 di(j) 的均方根,该值就是 i 的选择抖动 φS(i)(select jitter)。从时钟选择算法中还可以获得源 i 的源抖动 φR(i)(peer jitter)。
令 φmax 为选择抖动的最大值,φmin 为源抖动的最小值。当 φmax > φmin 时,去除 φmax 对应的源可以降低选择抖动,因此将去除该源。当 φmax < φmin 时,源抖动具有更大的影响,因此去除源并不能降低抖动,算法结束。
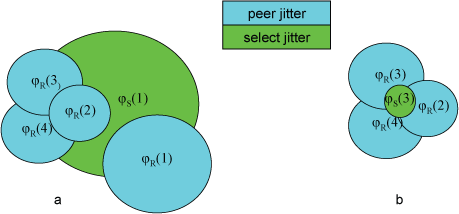
a 中,源 1 的选择抖动显著大于所有源的源抖动,因此移除该源。之后形成 b 的情形,此时最大的选择抖动小于源抖动,因此算法不再去除源,直接结束。
注意到在计算选择抖动时使用根距离 λ 作为权值,具有较小根距离的源抖动较小,因此算法更偏好对离根更近的源。
组合和平缓算法(Combine Algorithm and Mitigation Rules)
组合平缓算法在前述过程筛选出的时钟源中计算统计信息,并根据统计信息来生成对系统时钟的最终调整。这一部分由许多算法与规则组成,用户还可以设置偏好来代替算法的默认规则。
组合算法(Combine Algorithm)
组合算法计算出偏移和抖动的加权平均值,将该平均值作为系统时钟的调整(即系统时钟源,system peer)。权重设置为与根距离倒数有关的因子,该因子经过归一化,使得它们之和为 1。这一权值对根距离较小的时钟源有利,可以减少误差。
防时钟跳变算法(Anti-Clockhop Algorithm)
在候选时钟源之间差异较小时,可能会出现频繁更改系统时钟源的情况,导致时钟频繁跳变。为了减小系统时钟抖动,使时钟稳定,应当应用防时钟跳变算法。
在组合算法后将立即应用本算法,当原有系统时钟源不存在或与新时钟源相同时,更改系统时钟源。如果新时钟源于原有系统时钟源参数差异超过跳变阈值,则改变系统时钟源,并重置阈值至默认值;否则,不改变系统时钟源,并将跳变阈值缩小一半。最终,系统时钟源会改变为新时钟源,但本算法降低了改变的频率。
首选时钟源(Prefer Peer)
用户可以设置首选时钟源,当给出的时钟源列表中包含首选时钟源时,则不应用组合算法,而直接将首选时钟源作为系统时钟源。
平缓规则(Mitigation Rules)
平缓规则用于在候选时钟源为空或者其他特殊情况下给出临时方案,具体规则如下:
- 如果候选为空且调制解调器存在,则将调制解调器加入候选列表。如果没有调制解调器且本地时间源存在,则将本地时间源加入候选列表。如果没有本地时间源,则将孤立系统的源加入候选列表。如果上述条件都不满足,则不改变系统时钟;
- 如果候选中包含首选时钟源,则将首选时钟源作为系统时钟源;否则,应用组合算法计算出系统时钟源;
- 如果存在 PPS 源(每秒发出脉冲的高精度脉冲设备),且系统时钟偏差小于 0.4s,且候选列表中存在首选时钟源或首选时钟源为 PPS 源,则选择 PPS 源作为系统时钟源,无视上述计算出的数据。
如果上述规则都不符合,则系统时钟不会改变。
平缓规则给出了在网络中无法找到时钟源时的替代方案,且优先选择本地的高精度时钟设备,是综合了各种条件给出最优方案的规则。
时钟调节算法(Clock Discipline Algorithm)
最后,选定了系统的参考时钟源,并给出了系统的偏差,需要根据偏差校准系统时钟。这一过程通过时钟调节算法实现。
算法通过负反馈系统 PLL/FLL 将校准应用到时钟上。为避免时钟跳变,该系统将校准延长到一段时间上,使得这段时间上系统时钟改变对时间的积分为偏差量。在 PLL 模式下,系统通过调整频率(时钟增加的速度)应用偏差,FLL 模式下类似。
但初始化时,时钟的偏差有可能较大,需要快速更新。时钟调解算法规定了特殊规则以快速初始化时钟。
结语
经过了复杂曲折的过程后,你的设备最终获得了准确的时间,并不断校准时间。在此之后,依赖时间运作的应用启动,人们的作息也有了更准确的时间可以参考。
时间是这个世界上极为重要的信息,NTP 协议至今仍然管理着这一重要信息,也证明了其设计严谨精妙,足够满足对时间准确性越来越高的要求。
在进行应用开发的时候,从系统时钟获取时间是很容易的,但我们很少了解过系统内部是如何处理时间的。而同样作为互联网应用之一的 NTP 协议为我们打开了一个窗户,使我们从互联网走进时间处理,了解时间内部的原理与机制。互联网中传输与存储着海量的信息,在底层支撑这一系统的原理众多且强大,作为互联网人,不妨以互联网为契机学习这些原理,进而探索与互联网相连接的更广阔的世界。
参考资料
- Network Time Foundation’s NTP Support Wiki. http://support.ntp.org/bin/view/Main/WebHome
- NTP: The Network Time Protocol. http://ntp.org/
- 维基百科. 网络时间协议. https://zh.wikipedia.org/wiki/%E7%B6%B2%E8%B7%AF%E6%99%82%E9%96%93%E5%8D%94%E5%AE%9A
- The Network Time Protocol (NTP) Distribution. https://www.eecis.udel.edu/~mills/ntp/html/index.html
- How NTP Works. https://www.eecis.udel.edu/~mills/ntp/html/warp.html
- Stack Overflow. How does NTP Clock Discipline work?. https://stackoverflow.com/questions/19352740/how-does-ntp-clock-discipline-work
- 知乎 郭松成. 【网络干货】NTP时间同步技术详解. https://zhuanlan.zhihu.com/p/138339057
- Network Working Group. RFC1059 Network Time Protocol (Version 1) Specification and Implementation. https://tools.ietf.org/html/rfc1059
- Internet Engineering Task Force (IETF). RFC5905 Network Time Protocol Version 4: Protocol and Algorithms Specification. https://tools.ietf.org/html/rfc5905
- Server Fault. What is NTP dispersion and how do I control it?. https://serverfault.com/questions/768280/what-is-ntp-dispersion-and-how-do-i-control-it
- The Linux Kernal Documentation. PPS – Pulse Per Second. https://www.kernel.org/doc/html/latest/driver-api/pps.html
- Wikipedia. Phase-locked loop. https://en.wikipedia.org/wiki/Phase-locked_loop
文中部分内容引用自网络内容,引用源皆在参考资料中列出,感谢作者的分享。
