
NTP 网络时间协议
By KSkun, 2020/7/20 NTP(Network Time Procotol …
May all the beauty be blessed.
![[CSP-S2 2019]树的重心 题解](https://ksmeow.moe/wp-content/uploads/2020/05/shirobako2-6.jpg)
题目地址:洛谷:P5666 树的重心 – 洛谷 | 计算机科学教育新生态
小简单正在学习离散数学,今天的内容是图论基础,在课上他做了如下两条笔记:
课后老师给出了一个大小为 $n$ 的树 $S$,树中结点从 $1 \sim n$ 编号。小简单的课后作业是求出 $S$ 单独删去每条边后,分裂出的两个子树的重心编号和之和。即:
$$ \sum\limits_{(u,v) \in E} \left( \sum\limits_{1 \leq x \leq n \atop 且 x 号点是 S’_u 的重心} x + \sum\limits_{1 \leq y \leq n \atop 且 y 号点是 S’_v 的重心} y \right) $$
上式中,$E$ 表示树 $S$ 的边集,$(u,v)$ 表示一条连接 $u$ 号点和 $v$ 号点的边。$S’_u$ 与 $S’_v$ 分别表示树 SSS 删去边 $(u,v)$ 后,$u$ 号点与 $v$ 号点所在的被分裂出的子树。
小简单觉得作业并不简单,只好向你求助,请你教教他。
给定一棵 $n$ 个点的树,求树上每一条边 $(u,v)$ 删去后得到两个子树的所有重心编号之和。
输入格式:
本题包含多组测试数据
第一行一个整数 $T$ 表示数据组数。
接下来依次给出每组输入数据,对于每组数据:
第一行一个整数 $n$ 表示树 $S$ 的大小。
接下来 $n-1$ 行,每行两个以空格分隔的整数 $u_i, v_i$,表示树中的一条边 $(u_i,v_i)$。
输出格式:
共 $T$ 行,每行一个整数,第 $i$ 行的整数表示:第 $i$ 组数据给出的树单独删去每条边后,分裂出的两个子树的重心编号和之和。
输入样例 #1:
2 5 1 2 2 3 2 4 3 5 7 1 2 1 3 1 4 3 5 3 6 6 7
输出样例 #1:
32 56
| 测试点编号 | $n=$ | 特殊性质 |
|---|---|---|
| $1 \sim 2$ | 7 | 无 |
| $3 \sim 5$ | 199 | 无 |
| $6 \sim 8$ | 1999 | 无 |
| $9 \sim 11$ | 49991 | A |
| $12 \sim 15$ | 262143 | B |
| $16$ | 99995 | 无 |
| $17 \sim 18$ | 199995 | 无 |
| $19 \sim 20$ | 299995 | 无 |
表中特殊性质一栏,两个变量的含义为存在一个 $1 \sim n$ 的排列 $p_i \ (1 \leq i \leq n)$,使得:
对于所有测试点:$1 \leq T \leq 5 , 1 \leq u_i,v_i \leq n$。保证给出的图是一个树。
参考资料:
可能用到的记号:
拿到这个题目之后,第一个想法是枚举树上的每条边,其两端点对应的子树在树的 DFS 分别对应一个和最多两个区间。对于有根树而言,求子树中重心,就相当于求子树中最大儿子大小 $f(u)=\max\limits_{v \in \mathrm{son}(u)}\{ \mathrm{size}(v) \}$ 与父节点对应子树大小 $g(u)=n-\mathrm{size}(u)$ 二者中较大值的最小值 $\min\limits_{u \in \boldsymbol{V}(S)} \{ \max\{f(u),g(u)\} \}$ 对应的点 $u$。但这种想法情况众多,因为删边会影响两端点对应子树的 $f$ 值和 $g$ 值,它们的处理比较麻烦,目前为止并没能研究出来。
接下来要介绍的是一种「正难则反」的方法,即枚举边不是好做的方法,则枚举点,考虑其作为某种情况中的重心的次数。
下文中会以如 #标记 1# 的形式进行标记以建立上下文描述与实现代码之间的联系,请合理利用标记。
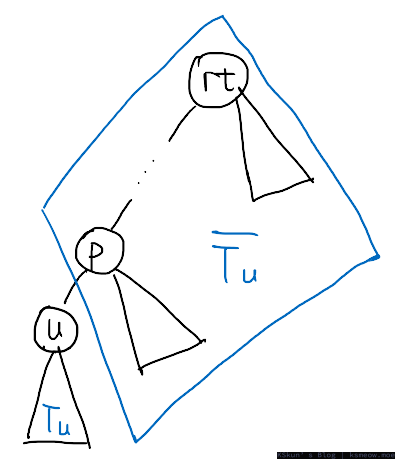
当 $u$ 不是根时,如上图,要让点 $u$ 成为某种情况下的重心,假设 $u$ 的所有儿子对应的子树 $\boldsymbol{T}(u)$ 都满足要求,只需要在除 $u$ 对应子树的部分 $\overline{T(u)}$ 删去一条边减小它的大小即可。记 $u$ 对应子树大小 $p=\mathrm{size}(u)$,$u$ 的最大儿子对应子树大小 $q=\mathrm{size}[\mathrm{mxson}(u)]$,删去一条边后从 $\overline{T(u)}$ 中移除的子树大小为 $r$。根据重心的定义,有以下条件成立:
$$ \begin{cases}
n-r-p \leq \left\lfloor \dfrac{n-r}{2} \right\rfloor, & u 的父亲对应的子树(即 \overline{T(u)} \backslash T(o))满足重心定义, \\
q \leq \left\lfloor \dfrac{n-r}{2} \right\rfloor, & u 的最大儿子对应子树满足重心定义.
\end{cases} $$
将分母的 2 乘到另一边上,再将 $r$ 单独整理出来,可以得到下式
$$ n – 2p \leq r \leq n – 2q $$
当 $r$ 不包括 $u$ 到树根路径(即图中的链 $rt, \dots, p$)上的点时,记删掉的边中远离 $u$ 的端点为 $o$,则$r = \mathrm{size}(o)$,因此只要构建出 $\overline{T(u)}$ 所有点 $\mathrm{size}$ 值的权值线段树或权值树状数组,就能很方便地查到落在区间 $[n-2p, n-2q]$ 区间内的 $r$ 值有多少个,而这就是 $u$ 点作为重心的情况数。#标记 1#
但 $r$ 也有可能包括 $u$ 到树根路径上的点,记删掉的边为 $(o_1, o_2)$,其中 $o_1$ 离 $u$ 更近,而 $o_2$ 离 $u$ 更远(即这条边在 $u$ 到树根的链上,且 $o_1$ 比 $o_2$ 更深),此时对应的删掉的子树大小应该为 $n-\mathrm{size}(o_1)$。在上文提到的树状数组中,应当删去 $\mathrm{size}(o_2)$ 一项,而加入 $[n-\mathrm{size}(o_1)]$ 一项。这个修正可以在 DFS 计算树状数组时维护好。#标记 2#
如果每次枚举一个点 $u$ 都动态地处理出所需的树状数组,复杂度不是很优,因此可以采用预先对原树全树的 $\mathrm{size}$ 值建树状数组,之后再排除 $u$ 对应子树中被错误统计进去的答案。实现排除错误答案可以用一个 DFS 进行计算,动态地往一个树状数组里添加 $\mathrm{size}$ 值,在 DFS 进入 $u$ 的子树前记下此时的答案,$u$ 子树计算完成后再记下此时的答案,前后答案之差即为 $u$ 点的错误答案,从 $u$ 作为重心的次数里减去这一错误情况即可。在这个 DFS 中,上一段中的修正(#标记 2#)也可以同时进行。#标记 3#
接下来分析上述方法的正确性。上述方法需要假定 $u$ 的所有儿子对应的子树 $\boldsymbol{T}(u)$ 都满足 $u$ 是重心时的要求,为了实现这一要求,必须有 $n-\mathrm{size}(u) \geq \mathrm{size}[\mathrm{mxson}(u)]$ 总是成立。不妨以全树的重心为根,这样就有 $\mathrm{size}(u) \leq \lfloor n/2 \rfloor$ 总是成立,而上式同时成立。这样就能保证当 $u$ 是重心时删掉的边一定不在 $u$ 的子树中,而是在 $\overline{T(u)}$ 中,实现了统计答案的不重不漏。
而上述方法带来了一个麻烦,记树根为 $rt$,该点的答案无法如上计算,因为该点对应的 $\overline{T(rt)} = \emptyset$,需要删掉的边一定在 $rt$ 的子树中。
不妨把情况分为要切掉的子树在根的最大儿子子树中和不在最大儿子子树中,分别讨论。记最大儿子子树大小为 $s_1=\mathrm{size}[\mathrm{mxson}(rt)]$,次大儿子子树大小为 $s_2$,删边后移除的子树大小为 $r$。
当切掉后的最大儿子子树大小 $s’_1=s_1-r$ 仍不小于次大儿子子树大小,即 $s’_1 \geq s_2 \Rightarrow r \leq s_1 – s_2$ 时,$rt$ 仍然是此时树的重心。下面证明这一结论,已知 $s_1 \leq \lfloor n/2 \rfloor \Rightarrow 2s_1 \leq n$,要证 $s_1 – r \leq \lfloor (n-r)/2 \rfloor \Rightarrow 2s_1 \leq n + r$,由于 $r>0$,待证式显然成立。
$s’_1<s_2$ 时,原来的次大儿子子树就变成了现在的最大儿子子树,必须满足 $s_2 \leq \lfloor (n-r)/2 \rfloor$,即 $s_1 – s_2 < r \leq n – 2s_2$。
综上,要使 $rt$ 仍是树的重心,必须满足 $r \leq n-2s_2$,可以最后单独对最大儿子子树 DFS,暴力判断每个点的 $\mathrm{size}$ 值是否满足要求即可。#标记 4#
最大儿子子树必须满足 $s_1 \leq \lfloor (n-r)/2 \rfloor$,即 $r \leq n – 2s_1$。可以和上面相似地,单独 DFS 暴力统计这些子树中每个点的 $\mathrm{size}$ 值是否满足要求。#标记 5#
到此为止,我们推出了本题所有情况的解法,下面整理一下思路,便于实现。
首先,由于解法中需要使用子树大小、最大儿子子树、根的次大儿子子树这些信息,可以用一个 DFS 计算出所有这些信息。有了子树大小信息,找出全树重心也不是难事。需要注意,在找出重心后,由于换根,这些信息还需要以重心为根重新计算一遍。
有了信息之后,就可以计算除了根之外的答案。用一个数组存储每个点作为重心的次数,用 DFS 计算答案。首先根据上文描述(#标记 2#),我们需要修正树状数组中当前点 $u$ 父节点的 $\mathrm{size}$ 为 $[n-\mathrm{size}(u)]$,然后查询区间落在 $[n-2\mathrm{size}(u), n-2\mathrm{size}[\mathrm{mxson}(u)]]$ 中的 $\mathrm{size}$ 值(#标记 1#)。另外为了排除错误情况,需要另开一个树状数组动态维护 $\mathrm{size}$ 值,错误情况数就是 DFS 深入儿子前后的答案之差,计算并修正答案即可(#标记 3#)。
下一步,计算根的答案。利用一个 DFS,在根的最大儿子子树中找到落在 $[1, n-2\mathrm{s_2}]$ 之内的 $\mathrm{size}$ 值数量(#标记 4#),和根的其他儿子子树中落在 $[1, n-2\mathrm{s_1}]$之内的 $\mathrm{size}$ 值数量(#标记 5#),两者之和便是根的答案。
最后,将出现次数与点的编号相乘加和就可得到最终答案。需要注意的是,答案可能过大,需要用 long long 存储与输出。
上述过程中,我们使用了一共三个 DFS,其中处理子树大小等信息的 DFS 复杂度为 $O(n)$,利用树状数组求根以外点答案的 DFS 复杂度为 $O(n \log n)$,求根答案的 DFS 复杂度为 $O(n)$,因此总复杂度为 $O(n \log n)$。
由于用 vector 存图,只有开 O2 能过。
// Code by KSkun, 2020/5
#include <cstdio>
#include <cctype>
#include <cstring>
#include <algorithm>
#include <utility>
#include <vector>
typedef unsigned long long LL;
typedef std::pair<int, int> PII;
using std::vector;
inline char fgc() {
static char buf[100000], *p1 = buf, *p2 = buf;
return p1 == p2 && (p2 = (p1 = buf) + fread(buf, 1, 100000, stdin), p1 == p2)
? EOF : *p1++;
}
inline LL readint() {
register LL res = 0, neg = 1; register char c = fgc();
for (; !isdigit(c); c = fgc()) if (c == '-') neg = -1;
for (; isdigit(c); c = fgc()) res = res * 10 + c - '0';
return res * neg;
}
inline char readsingle() {
char c;
while (!isgraph(c = fgc())) {}
return c;
}
const int MAXN = 300005;
// siz: 子树大小, mx_ch: 最大子树, mx2_1ch: 树根的次大子树, cnt: 作重心的次数
int T, n, ct, siz[MAXN], mx_ch[MAXN], mx2_1ch, cnt[MAXN];
vector<int> G[MAXN];
// 树状数组
class BinaryIndexedTree {
private:
int n, dat[MAXN];
int lowbit(int x) {
return x & -x;
}
public:
void init(int _n) {
n = _n;
memset(dat, 0, sizeof(dat));
}
void add(int idx, int val) {
if (idx <= 0) return;
for (int i = idx; i <= n; i += lowbit(i)) dat[i] += val;
}
int query(int idx) {
if (idx <= 0) return 0;
int res = 0;
for (int i = idx; i > 0; i -= lowbit(i)) res += dat[i];
return res;
}
} tree1, tree2;
// DFS 处理全树重心、子树大小、最大子树和树根的次大子树
void dfs_siz(int u, int par) {
siz[u] = 1;
mx_ch[u] = 0;
for (int v : G[u]) {
if (v == par) continue;
dfs_siz(v, u);
siz[u] += siz[v];
if (siz[mx_ch[u]] <= siz[v]) {
if (u == ct) mx2_1ch = mx_ch[u];
mx_ch[u] = v;
} else if (u == ct && siz[mx2_1ch] <= siz[v]) {
mx2_1ch = v;
}
}
if (siz[mx_ch[u]] <= n / 2 && n - siz[u] <= n / 2) ct = u;
}
// DFS 计算根之外点的次数
void dfs_cal(int u, int par) {
tree1.add(siz[par], -1); // 修正到根路径上各边两端子树大小 #标记 2#
tree1.add(n - siz[u], 1);
cnt[u] = tree1.query(n - 2 * siz[mx_ch[u]]) - tree1.query(n - 2 * siz[u] - 1); // #标记 1#
int bef = tree2.query(n - 2 * siz[mx_ch[u]]) - tree2.query(n - 2 * siz[u] - 1); // #标记 3# DFS 进入子树前
for (int v : G[u]) {
if (v == par) continue;
dfs_cal(v, u);
}
tree2.add(siz[u], 1);
int aft = tree2.query(n - 2 * siz[mx_ch[u]]) - tree2.query(n - 2 * siz[u] - 1);
cnt[u] -= aft - bef; // 用算子树前后 tree2 值的变化来计算子树中算入的情况 #标记 3#
tree1.add(siz[par], 1); // 消除修正的影响 #标记 2#
tree1.add(n - siz[u], -1);
}
// DFS 处理树根的方案
void dfs_rt(int u, int par, int lim) {
if (siz[u] <= lim) cnt[ct]++;
for (int v : G[u]) {
if (v == par) continue;
dfs_rt(v, u, lim);
}
}
int main() {
T = readint();
while (T--) {
// 输入
n = readint();
for (int i = 1; i <= n; i++) G[i].clear();
for (int i = 1, u, v; i <= n - 1; i++) {
u = readint(); v = readint();
G[u].push_back(v);
G[v].push_back(u);
}
// 预处理子树大小的权值树状数组
dfs_siz(1, 0); // 计算重心
dfs_siz(ct, 0); // 以重心为根计算树信息
tree1.init(n);
for (int i = 1; i <= n; i++) tree1.add(siz[i], 1);
tree2.init(n); // 计算除根之外点的次数
dfs_cal(ct, 0);
// 计算树根作重心的次数
cnt[ct] = 0;
dfs_rt(mx_ch[ct], ct, n - 2 * siz[mx2_1ch]); // 在根的最大子树中删边 #标记 4#
for (int ch : G[ct]) {
if (ch == mx_ch[ct]) continue;
dfs_rt(ch, ct, n - 2 * siz[mx_ch[ct]]); // 在根的其他子树中删边 #标记 5#
}
LL ans = 0;
for (int i = 1; i <= n; i++) ans += (LL) i * cnt[i];
printf("%lld\n", ans);
}
return 0;
}
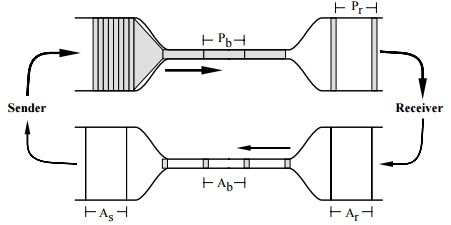
在网络上传输数据就像在水管中传输水流。假如我们要通过一根参数未知的水管输水,输得多了水管会爆裂,输得少了效率会降低,如何传输就是一个关键的问题。
也许上面的策略不是最好的策略,我们还可以制定更好的策略让调整的时间变短,从而使输水的效率增加。这种调整的策略就是拥塞控制算法。
根据上述场景,我们可以确定理想的拥塞控制算法满足的要求:
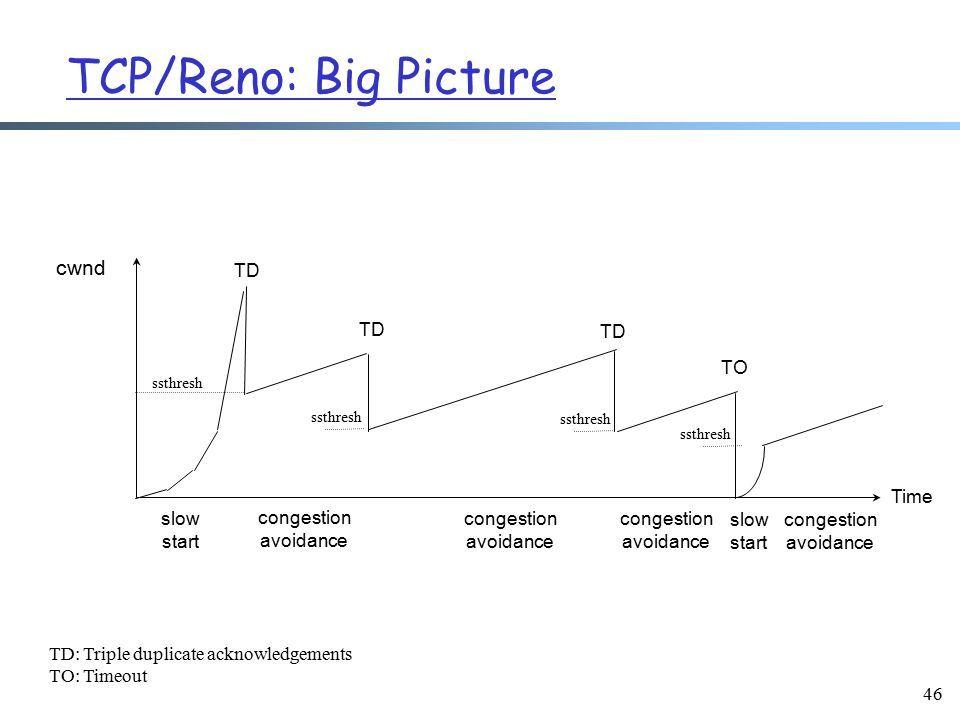
容易发现,上述几种算法都基于对丢包的判断和处理来进行拥塞控制。但是现在,丢包和拥塞的关系不那么紧密了,这些算法对于高延迟、高带宽、有一定丢包率的网络并不能达到最大传输效率。
既然丢包不是一种合适的判断方法,那么我们干脆不以丢包作为拥塞控制的依据,而是另寻其他信息。
Google 的研究人员对世界各地的大量 TCP 头部进行研究,确定了一种新的判断依据:瓶颈带宽(Bottleneck Bandwidth)和往返传播时间(Round-trip Propagation Time)。
考虑正常行驶的高速公路上突然发生了交通事故,这会导致局部通行速率降低,使得该处有车辆形成队列,从而使整条道路的通信速率降低。瓶颈带宽就是事故处的通行速率,而往返传播时间可以代表道路的长度。

丢包往往发生在图中缓存限制的区域,因此传统的 TCP 拥塞控制算法事实上只能将传输情况控制在该区域的边界附近。在此处,网络的延迟较大,缓存队列较慢,并不是最优方案。
通过 BBR 算法,我们可以以瓶颈带宽、往返传播时间来控制传输,使得网络中不存在缓存队列。这相当于控制向水管注水的速率,使水管中最细的一段恰好填满且没有水堆积在近端。
往返传播时间是链路的物理特性,可以视作不会改变,因此可以统计一段时间内的延迟最小值作为往返传播时间。
我们无法直接对瓶颈带宽进行计算,但可以用间接的方法。可以统计一个包从发出到收到 ACK 的时间间隔,在统计这段时间内的未确认包数,就可以计算出瓶颈带宽。
由于网络可能不断产生变化,瓶颈带宽、往返传播时间也应该进行实时的估计与调整。但当网络带宽增大时,上述过程并不会主动探测到带宽的增大。
BBR 使用 pacing 作为试探瓶颈带宽的方式,每次将窗口设置为比当前瓶颈带宽稍大的值,重新统计速率,即可判断当前状况处于临界点的哪一边。如果处于临界点右侧,则之后使用比瓶颈带宽稍小的值来消除网络中的队列。


BBR 在连接启动时,使用指数上升的规律增大发送速率,直到探测出瓶颈带宽。一旦找到瓶颈带宽,BBR 使用增大倍数的倒数消耗队列,之后保持上述稳定状态。

BBR 可以主动消耗网络中的队列,而传统的拥塞控制算法无法消耗网络中的队列,这是 BBR 的优势。

在新的连接建立之前,可能已有一些连接占满了瓶颈链路,BBR 需要平均分配链路,使得新建立的连接也可以分配到传输资源。
当一段时间内往返传播时间没有改变时,BBR 主动将窗口减小,使得网络中队列被消耗,其他连接得到了更小的往返传播时间,使得其他连接也主动减小窗口,之后同时开始回到原状态,从而实现资源的重新公平分配。

![[CSP-S2 2019]Emiya 家今天的饭 题解](https://ksmeow.moe/wp-content/uploads/2019/12/shirobako2-3.jpg)
题目地址:洛谷:P5664 Emiya 家今天的饭 – 洛谷 | 计算机科学教育新生态
Emiya 是个擅长做菜的高中生,他共掌握 $n$ 种烹饪方法,且会使用 $m$ 种主要食材做菜。为了方便叙述,我们对烹饪方法从 $1 \sim n$ 编号,对主要食材从 $1 \sim m$ 编号。
Emiya 做的每道菜都将使用恰好一种烹饪方法与恰好一种主要食材。更具体地,Emiya 会做 $a_{i,j}$ 道不同的使用烹饪方法 $i$ 和主要食材 $j$ 的菜($1 \leq i \leq n, 1 \leq j \leq m$),这也意味着 Emiya 总共会做 $\sum\limits_{i=1}^{n} \sum\limits_{j=1}^{m} a_{i,j}$ 道不同的菜。
Emiya 今天要准备一桌饭招待 Yazid 和 Rin 这对好朋友,然而三个人对菜的搭配有不同的要求,更具体地,对于一种包含 $k$ 道菜的搭配方案而言:
这些要求难不倒 Emiya,但他想知道共有多少种不同的符合要求的搭配方案。两种方案不同,当且仅当存在至少一道菜在一种方案中出现,而不在另一种方案中出现。
Emiya 找到了你,请你帮他计算,你只需要告诉他符合所有要求的搭配方案数对质数 $998,244,353$ 取模的结果。
一共有 $n$ 种烹饪方法和 $m$ 种主要食材,一道菜仅对应一种烹饪方法和一种主要食材。使用第 $i$ 种烹饪方法和第 $j$ 种主要食材,Emiya 可以做出 $a_{i,j}$ 道不同的菜。
求满足以下条件的菜的集合数:
输入格式:
第 1 行两个用单个空格隔开的整数 $n,m$。
第 2 行至第 $n + 1$ 行,每行 $m$ 个用单个空格隔开的整数,其中第 $i + 1$ 行的 $m$ 个数依次为 $a_{i,1}, a_{i,2}, \cdots, a_{i,m}$。
输出格式:
仅一行一个整数,表示所求方案数对 $998,244,353$ 取模的结果。
输入样例#1:
2 3 1 0 1 0 1 1
输出样例#1:
3
输入样例#2:
3 3 1 2 3 4 5 0 6 0 0
输出样例#2:
190
输入样例#3:
5 5 1 0 0 1 1 0 1 0 1 0 1 1 1 1 0 1 0 1 0 1 0 1 1 0 1
输出样例#3:
742
| 测试点编号 | $n=$ | $m=$ | $a_{i,j}<$ |
|---|---|---|---|
| $1$ | $2$ | $2$ | $2$ |
| $2$ | $2$ | $3$ | $2$ |
| $3$ | $5$ | $2$ | $2$ |
| $4$ | $5$ | $3$ | $2$ |
| $5$ | $10$ | $2$ | $2$ |
| $6$ | $10$ | $3$ | $2$ |
| $7$ | $10$ | $2$ | $2$ |
| $8$ | $10$ | $3$ | $1000$ |
| $9 \sim 12$ | $40$ | $2$ | $1000$ |
| $13 \sim 16$ | $40$ | $3$ | $1000$ |
| $17 \sim 21$ | $40$ | $500$ | $1000$ |
| $22 \sim 25$ | $100$ | $2000$ | $998,244,353$ |
对于所有测试点,保证 $1 \leq n \leq 100, 1 \leq m \leq 2000, 0 \leq a_{i,j} \lt 998,244,353$。
参考资料:题解 P5664 【Emiya 家今天的饭【民间数据】】 – Caro23333 的博客 – 洛谷博客
居然在 NOIP 级别的比赛中见到了计数 DP,很难想象以后的 NOIP 对于数学知识的考察会变成什么样。那个只有一道很水的数论/组合签到题的时代已经结束了。
首先本题是组合数学/计数类型的问题,这类题通常有两种解决方式:推公式或 DP,本题中可以采用 DP 求解。
接下来考虑如何设计 DP 状态。如果正面解决,就必须对每种主要食材的出现次数做小于集合大小的一半的限制,这需要记录下每种主要食材的出现次数,不是很可行。因此可以采用正难则反的策略,容易发现不合法的情况中只会有一种主要食材超过集合大小的一半,处理这个限制仅需记下一种主要食材的出现次数,问题变得简单了。
首先从一个较好解决的问题入手,由于答案=所有方案数-不合法方案数,我们需要知道所有的方案有多少种。
定义 $g(i, j)$ 表示前 $i$ 种烹饪方式中,每种最多选出一道菜的情况下,当前集合中有 $j$ 道菜的方案数,则决策为当前处理的第 $i$ 种烹饪方式是否选出一道菜,记 $s(i)$ 代表第 $i$ 种烹饪方式一共可做出的菜数,即 $s(i) = \sum\limits_{j=1}^m a_{i, j}$ 转移方程如下:
$$ g(i,j) = \underset{不选}{g(i-1, j)} + \underset{从 s(i) 道菜中选 1 种}{g(i-1,j-1) \cdot s(i)} $$
初始值为 $g(0, 0)=1$(什么都没做,有 $1$ 种方案),所有的方案数为 $\sum\limits_{i=1}^n g(n, i)$,由于集合不能为空,$g(n, 0)$ 的值不能加入方案数中。
这一部分的复杂度为 $O(n^2)$。
由于不合法的方案中,只有一种主要食材的数量会超过集合大小的一半,可以枚举超限的主要食材,而只记录下其他食材的数量之和,不分开记录。
定义 $f(in, j, k)$ 表示考虑前 $in$ 种烹饪方式,当前要超限的主要食材的出现次数为 $j$,其他主要食材的出现次数之和为 $k$。决策有三种:当前考虑的第 $in$ 种烹饪方式不选、选要超限的那种主要食材的菜或选其他主要食材的菜,记 $s(i)$ 代表第 $i$ 种烹饪方式一共可做出的菜数,且当前要超限的主要食材编号为 $im$,有转移方程:
$$ f(in, j, k) = \underset{不选}{f(in-1, j, k)} + \underset{选要超限的主要食材}{f(in-1, j-1,k) \cdot a_{in, im}} + \underset{选其他的主要食材}{f(in-1,j,k-1) \cdot [s(in)-a_{in,im}]} $$
将上述 DP 在以每一种主要食材为超限食材的情况下都计算一遍,对于 $im$ 这种食材为超限食材的情况,不合法的方案数为 $\sum\limits_{k < j} f(n, j, k)$。将这些不合法的方案数加起来就获得了总的不合法方案数了。但这种方式的复杂度是 $O(n^3m)$ 的,无法通过本题。
考虑优化上述方法,将不合法的方案满足的条件 $k < j$ 移项,得到表达式 $j-k > 0$,其实判断一个方案是否合法,仅需要判断 $j-k$ 的符号即可,我们考虑将之前状态中的 $j$ 和 $k$ 两个维度变为一维 $j-k$ 的值,这将会减少一层循环,使复杂度降至 $O(n^2m)$。
接下来考虑上面的改变会对转移方程造成什么样的影响,事实上,仅需将方程中的两维改为一维即可:
$$ f(in, j) = \underset{不选}{f(in-1, j)} + \underset{选要超限的主要食材}{f(in-1, j-1) \cdot a_{in, im}} + \underset{选其他的主要食材}{f(in-1,j+1) \cdot [s(in)-a_{in,im}]} $$
由于 $j-k$ 的值可以为负数,而数组下标不能为负数,因此下标应当处理为 $j-k+n$,以让下标的值非负。DP 的初始值为 $f(0, 0)=1$(什么都没做,其中第二维下标应处理为 $n$),对于每一种超限食材的情况,不合法的方案数为$\sum\limits_{j=1}^n f(n, j)$(第二维下标应处理为 $j + n$)。
最后,将所有方案数减去不合法方案数就得到了最终答案,总复杂度为 $O(n^2m)$。
// Code by KSkun, 2019/12
#include <cstdio>
#include <cctype>
#include <cstring>
#include <algorithm>
#include <utility>
typedef long long LL;
typedef std::pair<int, int> PII;
inline char fgc() {
static char buf[100000], * p1 = buf, * p2 = buf;
return p1 == p2 && (p2 = (p1 = buf) + fread(buf, 1, 100000, stdin), p1 == p2)
? EOF : *p1++;
}
inline LL readint() {
LL res = 0, neg = 1; char c = fgc();
for(; !isdigit(c); c = fgc()) if(c == '-') neg = -1;
for(; isdigit(c); c = fgc()) res = res * 10 + c - '0';
return res * neg;
}
inline char readsingle() {
char c;
while(!isgraph(c = fgc())) {}
return c;
}
const int MAXN = 105, MAXM = 2005;
const int MO = 998244353;
int n, m;
LL a[MAXN][MAXM], s[MAXN], f[MAXN][MAXN << 1], g[MAXN][MAXN];
inline LL A(int in, int im) { // 让方程不那么长的简化
return (s[in] - a[in][im] + MO) % MO;
}
int main() {
n = readint(); m = readint();
for (int i = 1; i <= n; i++) {
for (int j = 1; j <= m; j++) {
a[i][j] = readint();
s[i] = (s[i] + a[i][j]) % MO;
}
}
LL sum1 = 0, sum2 = 0;
for (int im = 1; im <= m; im++) {
memset(f, 0, sizeof(f));
f[0][n] = 1;
for (int in = 1; in <= n; in++) {
for (int j = n - in; j <= n + in; j++) {
f[in][j] = (f[in - 1][j] + f[in - 1][j - 1] * a[in][im] % MO + f[in - 1][j + 1] * A(in, im) % MO) % MO;
}
}
for (int i = 1; i <= n; i++) {
sum1 = (sum1 + f[n][n + i]) % MO;
}
}
g[0][0] = 1;
for (int i = 1; i <= n; i++) {
for (int j = 0; j <= n; j++) {
g[i][j] = g[i - 1][j];
if (j > 0) g[i][j] = (g[i][j] + g[i - 1][j - 1] * s[i] % MO) % MO;
}
}
for (int i = 1; i <= n; i++) {
sum2 = (sum2 + g[n][i]) % MO;
}
printf("%lld", (sum2 - sum1 + MO) % MO);
return 0;
}Copyright © 2017-2022 KSkun's Blog.
Authored by KSkun and his friends.

本博客内所有原创内容采用知识共享署名-相同方式共享 4.0 国际许可协议进行许可。引用内容如果侵权,请在此留言。
All original content in this blog is licensed under a Creative Commons Attribution-ShareAlike 4.0 International License.
If any reference content infringes your rights, please contact us.




![[CSP-S2 2019]划分 题解](https://ksmeow.moe/wp-content/uploads/2019/12/shirobako2-4-760x400.jpg)
![[CSP-J2 2019]纪念品 题解](https://ksmeow.moe/wp-content/uploads/2019/11/shirobako2-2-760x400.jpg)