![[CSP-J2 2019]加工零件 题解](https://ksmeow.moe/wp-content/uploads/2019/11/shirobako2-1-760x400.jpg)
[CSP-J2 2019]加工零件 题解
题目地址:洛谷:P5663 加工零件 – 洛谷 | 计算机科学教育新生态 题目 …
May all the beauty be blessed.
![[CSP-S2 2019]括号树 题解](https://ksmeow.moe/wp-content/uploads/2019/11/shirobako1-13.jpg)
题目地址:洛谷:P5658 括号树 – 洛谷 | 计算机科学教育新生态
本题中合法括号串的定义如下:
本题中子串与不同的子串的定义如下:
一个大小为 $n$ 的树包含 $n$ 个结点和 $n-1$ 条边,每条边连接两个结点,且任意两个结点间有且仅有一条简单路径互相可达。
小 Q 是一个充满好奇心的小朋友,有一天他在上学的路上碰见了一个大小为 $n$ 的树,树上结点从 $1 \sim n$ 编号,$1$ 号结点为树的根。除 $1$ 号结点外,每个结点有一个父亲结点,$u$($2 \le u \le n$)号结点的父亲为 $f_u$($1 \le f_u < u$)号结点。
小 Q 发现这个树的每个结点上恰有一个括号,可能是 ( 或 )。小 Q 定义 $s_i$ 为:将根结点到 $i$ 号结点的简单路径上的括号,按结点经过顺序依次排列组成的字符串。
显然 $s_i$ 是个括号串,但不一定是合法括号串,因此现在小 Q 想对所有的 $i$($1 \le i \le n$)求出,$s_i$ 中有多少个互不相同的子串是合法括号串。
这个问题难倒了小 Q,他只好向你求助。设 $s_i$ 共有 $k_i$ 个不同子串是合法括号串,你只需要告诉小 Q 所有 $i \times k_i$ 的异或和,即:
$$(1\times k_1)\ \text{xor}\ (2\times k_2)\ \text{xor}\ (3\times k_3)\ \text{xor}\ \cdots \ \text{xor}\ (n\times k_n)$$
其中 $\text{xor}$ 是位异或运算。
一棵 $n$ 个节点的树上每个节点有一个左括号或右括号,求出从树根 1 到每个节点的树链对应的括号序列中不同的合法子串个数。
输入格式:
从文件 brackets.in 中读入数据。
第一行一个整数 $n$,表示树的大小。
第二行一个长为 $n$ 的由 ( 与 ) 组成的括号串,第 $i$ 个括号表示 $i$ 号结点上的括号。
第三行包含 $n−1$ 个整数,第 $i$($1 \le i < n$)个整数表示 $i + 1$ 号结点的父亲编号 $f_{i+1}$。
输出格式:
输出到文件 brackets.out 中。
仅一行一个整数表示答案。
输入样例#1:
5 (()() 1 1 2 2
输出样例#1:
6
| 测试点编号 | $n \leq$ | 特殊性质 |
|---|---|---|
| $1 \sim 2$ | $8$ | $f_i=i-1$ |
| $3 \sim 4$ | $200$ | $f_i=i-1$ |
| $5 \sim 7$ | $2000$ | $f_i=i-1$ |
| $8 \sim 10$ | $2000$ | 无 |
| $11 \sim 14$ | $10^5$ | $f_i=i-1$ |
| $15 \sim 16$ | $10^5$ | 无 |
| $17 \sim 20$ | $5 \times 10^5$ | 无 |
首先考虑如何求出一个括号序列中不同的合法子串数目,这是一个比较经典的括号序列类 DP 问题,它的解法是这样的:
由于括号序列具有 $A$ 合法,则 $(A)$ 合法的可扩展性,因此可以使用栈来完成 DP 的转移。定义 DP 状态 $f(i)$ 表示括号序列 $S$ 中,以 $S_i$ 结尾的合法子串个数。如果 $S_i$ 是左括号,则将 $i$ 放入一个栈中;如果 $S_i$ 是右括号,则向前找到最近的未匹配的左括号位置 $j$ ,这样就可以完成一次匹配,即是 (A) 的状况,因此有以下转移
$$ f(i) = f(j-1)+1 $$
其中,多出来的 $1$ 个合法子串即是 (A) 这一个。向上找未匹配的过程可以用栈实现,在刚才左括号插入的栈中找到栈顶即是最近的未匹配左括号,随后由于该括号已匹配,因此将其弹出栈。
当这个问题上了树,仍然可以用类似的方法解决。同样地定义 $f(u)$ 为从 $1$ 到 $u$ 这条树链对应的括号序列中,以 $S_u$ 结尾的合法子串个数。在树链上向上找到最深的未匹配左括号结点即可。在 DFS 遍历树上节点的过程中,维护这个栈的信息即可。这一部分的细节可以参考代码中的注释。
由于状态定义仅为 $u$ 结尾的合法子串个数, $u$ 节点的答案应是从 $1$ 到 $u$ 的树链上所有节点的 DP 值之和,因此还要做一次 DFS 完成求和。
由于答案可能很大,因此在计算 $u \times f(u)$ 时需要转型成 long long 计算。
UPD:更换了 unsigned long long ,可以通过官方数据。
// Code by KSkun, 2019/11
#include <cstdio>
#include <cctype>
#include <algorithm>
#include <vector>
#include <stack>
#include <utility>
typedef unsigned long long LL;
typedef std::pair<int, int> PII;
inline char fgc() {
static char buf[100000], * p1 = buf, * p2 = buf;
return p1 == p2 && (p2 = (p1 = buf) + fread(buf, 1, 100000, stdin), p1 == p2)
? EOF : *p1++;
}
inline LL readint() {
LL res = 0, neg = 1; char c = fgc();
for(; !isdigit(c); c = fgc()) if(c == '-') neg = -1;
for(; isdigit(c); c = fgc()) res = res * 10 + c - '0';
return res * neg;
}
inline char readsingle() {
char c;
while(!isgraph(c = fgc())) {}
return c;
}
const int MAXN = 500005;
int n, fa[MAXN];
LL f[MAXN];
char str[MAXN];
std::vector<int> gra[MAXN];
std::stack<int> sta;
void dfs1(int u) {
int t = -1;
if (str[u] == ')' && !sta.empty()) {
t = sta.top();
sta.pop();
f[u] += f[fa[t]] + 1;
} else if (str[u] == '(') {
sta.push(u);
}
for (int v : gra[u]) {
dfs1(v);
}
if (str[u] == ')' && t != -1) sta.push(t);
else if (str[u] == '(') sta.pop();
}
void dfs2(int u) {
f[u] += f[fa[u]];
for (int v : gra[u]) {
dfs2(v);
}
}
int main() {
scanf("%d", &n);
scanf("%s", str + 1);
for (int i = 2; i <= n; i++) {
scanf("%d", &fa[i]);
gra[fa[i]].push_back(i);
}
dfs1(1);
dfs2(1);
LL ans = 0;
for (int i = 1; i <= n; i++) {
ans ^= i * f[i];
}
printf("%llu", ans);
return 0;
}![[IOI2007]Pairs 题解](https://ksmeow.moe/wp-content/uploads/2019/11/shirobako1-11.jpg)
题目地址:洛谷:P4648 [IOI2007] pairs 动物对数 – 洛谷 | 计算机科学教育新生态、BZOJ:Problem 1807. — [Ioi2007]Pairs 彼此能听得见的动物对数
Mirko and Slavko are playing with toy animals. First, they choose one of three boards given in the figure below. Each board consists of cells (shown as circles in the figure) arranged into a one, two or three dimensional grid.
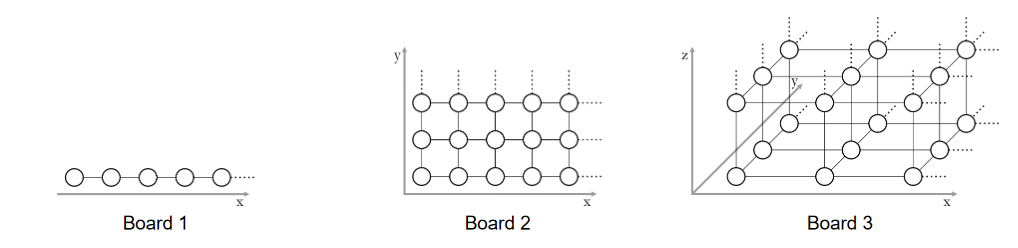
Mirko then places N little toy animals into the cells.
The distance between two cells is the smallest number of moves that an animal would need in order to reach one cell from the other. In one move, the animal may step into one of the adjacent cells (connected by line segments in the figure).
Two animals can hear each other if the distance between their cells is at most D. Slavko’s task is to calculate how many pairs of animals there are such that one animal can hear the other.
Write a program that, given the board type, the locations of all animals, and the number D, finds the desired number of pairs.
在一维、二维、三维空间中有 $N$ 个点,请你求出其中曼哈顿距离不超过 $D$ 的点对数。
输入格式:
The first line of input contains four integers in this order:
Each of the following N lines contains B integers separated by single spaces, the coordinates of one toy animal.
Each coordinate will be between 1 and M (inclusive).
More than one animal may occupy the same cell.
输出格式:
Output should consist of a single integer, the number of pairs of animals that can hear each other. Note: use a 64-bit integer type to calculate and output the result (long long in C/C++, int64 in Pascal).
输入样例#1:
1 6 5 100 25 50 50 10 20 23
输出样例#1:
4
输入样例#2:
2 5 4 10 5 2 7 2 8 4 6 5 4 4
输出样例#2:
8
输入样例#3:
3 8 10 20 10 10 10 10 10 20 10 20 10 10 20 20 20 10 10 20 10 20 20 20 10 20 20 20
输出样例#3:
12
这是 IOI 问题中的一道“胶水题”。实际上 B=1 、 B=2 、 B=3 三种情况使用的算法都并不相同,但又能通过低维最优解扩展(实际上是对多出来的一维做暴力)得到一个不那么优的做法骗到分,个人觉得这也是一种挺不错的命题方式。
很容易发现,将一维点按照坐标从小到大排序得到序列 $\{a_i\}$ ,对于元素 $a_i$ ,记到这个点距离不超过 $D$ 的坐标最小的点为 $a_j$ ,则下标在 $[j, i]$ 范围内的点都是当元素 $a_i$ 作为右边的那个点(只统计 $a_i$ 作为右边的情况是为了去重)时构成的点对的左边的那个点的选择, $a_i$ 对答案的贡献值为 $(i-j)$ 。此处的 $j$ 随 $i$ 的增大而增大,因此可以应用双指针算法。
指针 $i$ 和 $j$ 各自的移动次数都不超过 $N$ ,因此复杂度为 $O(N)$ 。
如果将扫描线应用到 $x$ 坐标为定值的每一“行”中,也是能解决二维问题的,因为每一行 $y$ 坐标的区间长度不会改变。但这样做复杂度会高达 $O(N^2D)$ ,与 $D$ 有关,不是一个可取的方法。
为了让问题更好处理,这里使用了转换坐标系的技巧。容易发现的性质是,一个二维点所有距离在 $D$ 之内的点构成了一个倾斜 $45^{\circ}$ 的正方形,如果把坐标系旋转 $45^{\circ}$ 就可以转成一个边与坐标轴平行的正方形,就好处理了一些。然而因为旋转坐标系需要涉及 $\frac{\sqrt{2}}{2}$ 的计算,并不是那么好写。
一个更好实现的方法是引入切比雪夫距离。
定义 1 两个 $n$ 维空间点的切比雪夫距离定义为所有维度坐标值之差的绝对值的最大值,即两个二维点 $(x_1, y_1), (x_2, y_2)$ 的切比雪夫距离为 $\text{dist} = \max\{ |x_1-x_2|, |y_1-y_2| \}$ 。
引理 1 两个二维点 $(x_1, y_1), (x_2, y_2)$ 的曼哈顿距离等于 $(x_1+y_1, x_1-y_1), (x_2+y_2, x_2-y_2)$ 两个点的切比雪夫距离。
引理 1 的证明可以将两种距离分情况展开成表达式,容易观察到两个距离的表达式完全等价。
对二维空间的所有点做坐标转换(以下所有坐标都为转换后的坐标),则曼哈顿距离上的限制就变成了切比雪夫距离上的限制,此时与点 $P$ 距离不超过 $D$ 的点就变成了一个长为 $2D$ ,以 $P$ 为几何中心的一个正方形,这将问题转化为在这个正方形中求点数的问题,可以用扫描线来解决。
用一个树状数组(也可使用线段树或其他功能相同的数据结构)存储在规定的 $x$ 坐标范围内,每个 $y$ 坐标上的点数。点 $(x_i, y_i)$ 的贡献即为树状数组中 $[y_i-D, y_i+D]$ 范围内的点数,计算前要先将树状数组中 $x_j < x_i-D$ 的点 $(x_j, y_j)$ 移除,计算后要将当前计算的点 $(x_i, y_i)$ 插入树状数组。
树状数组的插入、删除、查询操作不会超过 $3N$ 次,而树状数组的大小为坐标数值上限 $M$ ,因此该算法的复杂度为 $O(N \log M)$ 。
由于坐标转换时 $(x_i-y_i)$ 可能为负值,不妨在树状数组中将其存储为 $(x_i-y_i+M)$ ,计算时再复原回去即可,细节见代码。
你依然可以将 B=2 的扫描线做法扩展到三维,原理是对 $z$ 坐标暴力,固定 $z$ 坐标可以得到一个平面,在该平面用该平面的修正距离 限制 (对于三维点 $(x, y, z)$ ,它在 $z$ 坐标为 $z’$ 的平面内的距离限制为 $(D-|z-z’|)$ )做扫描线即可。但此时的复杂度依然与 $D$ 有关,不是可取的方法。
观察到 $M$ 的范围很小,实际上 $z$ 坐标只需要检查至多 $M$ 次,也就是说当 $M$ 大于 $3M$ 时就无意义了, $D$ 的值可以变得很小。
而且坐标值的范围变小为我们应用二维前缀和提供了便利,分别对每个固定 $z$ 坐标得到的平面上的点做一次前缀和,利用前缀和的值可以单次 $O(1)$ 地查到一个正方形中的点数。这可以替代扫描线中对树状数组的查询操作,且前缀和都进行了预处理,不需要维护树状数组了。
但这导致了一个问题,在查询点所在的 $z$ 坐标固定形成的平面中查询的答案存在重复,因此要单独做一次去重,细节见代码。
求前缀和的复杂度为 $O(M^3)$ ,计算的复杂度为 $O(NM)$ ,因此最终复杂度为 $O(NM)$ 。
// Code by KSkun, 2019/10
#include <cstdio>
#include <cctype>
#include <cstring>
#include <algorithm>
#include <vector>
typedef long long LL;
inline char fgc() {
static char buf[100000], * p1 = buf, * p2 = buf;
return p1 == p2 && (p2 = (p1 = buf) + fread(buf, 1, 100000, stdin), p1 == p2)
? EOF : *p1++;
}
inline LL readint() {
LL res = 0, neg = 1; char c = fgc();
for(; !isdigit(c); c = fgc()) if(c == '-') neg = -1;
for(; isdigit(c); c = fgc()) res = res * 10 + c - '0';
return res * neg;
}
inline char readsingle() {
char c;
while(!isgraph(c = fgc())) {}
return c;
}
const int MAXN = 100005;
int B, n, D, m;
int sum[80][505][505];
class BinaryIndexedTree {
private:
inline static int lowbit(int x) {
return x & -x;
}
int N;
std::vector<int> dat;
public:
BinaryIndexedTree(int _N = 240) {
N = _N;
dat.assign(N, 0);
}
void add(int pos, int value) {
for (int i = pos; i < N; i += lowbit(i)) {
dat[i] += value;
}
}
int query(int pos) {
if (pos <= 0) return 0;
int res = 0;
for (int i = pos; i > 0; i -= lowbit(i)) {
res += dat[i];
}
return res;
}
void clear() {
dat.clear();
dat.assign(N, 0);
}
};
struct Pos {
int x, y, z;
Pos(int _x = 0, int _y = 0, int _z = 0): x(_x), y(_y), z(_z) {}
inline bool operator<(const Pos& rhs) const {
return z != rhs.z ? z < rhs.z : (x != rhs.x ? x < rhs.x : y < rhs.y);
}
} pos[MAXN];
int main() {
B = readint(); n = readint(); D = readint(); m = readint();
for (int i = 1, x, y; i <= n; i++) {
x = readint();
if (B >= 2) y = readint();
if (B >= 3) pos[i].z = readint();
// 坐标转换
if (B >= 2) {
pos[i].x = x + y;
pos[i].y = x - y + m; // 避免产生负值
} else {
pos[i].x = x;
}
}
std::sort(pos + 1, pos + n + 1);
LL ans = 0;
if (B == 1) { // 双指针
int lft = 1;
for (int i = 1; i <= n; i++) {
lft = std::lower_bound(pos + lft, pos + i, Pos(pos[i].x - D)) - pos;
ans += i - lft;
}
} else if (B == 2) { // 扫描线
BinaryIndexedTree bit(225005); int lst = 1;
bit.add(pos[1].y, 1);
for (int i = 2; i <= n; i++) {
while (lst < i && pos[i].x - pos[lst].x > D) {
bit.add(pos[lst].y, -1);
lst++;
}
int l = std::max(0, pos[i].y - D), r = std::min(m * 2, pos[i].y + D);
int res = bit.query(r) - bit.query(l - 1);
ans += res;
bit.add(pos[i].y, 1);
}
} else { // 二维前缀和
D = std::min(D, m * 3); // 缩小 D 的范围
for (int i = 1; i <= n; i++) {
sum[pos[i].z][pos[i].x][pos[i].y]++;
}
for (int i = 1; i <= m; i++) {
for (int j = 1; j < 505; j++) {
for (int k = 1; k < 505; k++) {
sum[i][j][k] += sum[i][j - 1][k] + sum[i][j][k - 1] - sum[i][j - 1][k - 1];
}
}
}
LL ans2 = 0;
for (int i = 1; i <= n; i++) {
for (int j = std::max(1, pos[i].z - D); j < pos[i].z; j++) {
int d = D - (pos[i].z - j); auto arr = sum[j];
int x1 = std::max(1, pos[i].x - d), y1 = std::max(1, pos[i].y - d), x2 = pos[i].x + d, y2 = pos[i].y + d;
ans += arr[x2][y2] - arr[x1 - 1][y2] - arr[x2][y1 - 1] + arr[x1 - 1][y1 - 1];
}
auto arr = sum[pos[i].z];
int x1 = std::max(1, pos[i].x - D), y1 = std::max(1, pos[i].y - D), x2 = pos[i].x + D, y2 = pos[i].y + D;
ans2 += arr[x2][y2] - arr[x1 - 1][y2] - arr[x2][y1 - 1] + arr[x1 - 1][y1 - 1];
}
ans2 -= n; // 去重
ans += ans2 / 2;
}
printf("%lld", ans);
return 0;
}
冰岩作坊的各种产品都与互联网相关,不可避免地会用到Go语言的网络框架,其中,gin就是一个使用广泛的框架。
新人任务中,我用gin完成了若干实例的开发,学习了gin的一些使用方法。这篇文章整理了我接触过的部分功能。由于使用的场景有限,这里只列举了有限的几个内容。
Router,即路由器(不是一个小盒子那个),功能是监听某个端口的HTTP请求,并根据请求的URL用不同的Handler处理。
在gin中,可以通过gin.Default()获得一个Router,它的类型是gin.Engine。你可以将Handler和Middleware添加到这个Router上,使它按照规则处理请求。
对于Handler,你可以通过Router的GET、POST等方法绑定对于某一类型请求的Handler函数,并指定绑定的URL。
对于Middleware,你可以通过Router的Use方法绑定一个Middleware函数。一般在使用Middleware的时候,常常使用Group对某一URL的请求分类,在绑定Middleware的同时绑定Handler。
Handler,即处理函数,功能是处理指定的请求,并根据请求给出相应的响应。
在gin中,Handler应当是一个接受一个*gin.Context类型参数的函数。使用JSON进行C/S通信是一种很常用的方法,你可以通过gin.Context的BindJSON方法将请求体中的JSON内容解析进指定结构体中。结构体内的变量需要设置json反射标签。以下给出一个使用例。
type ReqType struct {
var Data int `json:"data"`
}
func main() {
router := gin.Default()
router.POST("/", func(context *gin.Context) {
var req ReqType
err := context.BindJSON(&req)
if err != nil {
fmt.Println(err.Error())
return
}
fmt.Println(req.Data)
})
_ = router.Run()
}gin也可以很方便地使用JSON作出响应。gin.H是一个对map的简写,你可以用它简单地创建一个map,并用context.JSON方法作出响应。以下给出一个使用例。
type ReqType struct {
var Data int `json:"data"`
}
func main() {
router := gin.Default()
router.POST("/", func(context *gin.Context) {
var req ReqType
err := context.BindJSON(&req)
if err != nil {
fmt.Println(err.Error())
return
}
context.JSON(http.StatusOK, gin.H{
"message": req.Data,
})
})
_ = router.Run()
}Handler还可以处理其他类型的请求,如GET、OPTIONS等,由于我没有接触过这些请求的用法,这里便留空了。
Middleware,即中间件,功能是在请求发给Handler之前对请求进行一些处理,比如验证权限。在我的实践中,我实现了一个验证JWT的Middleware,用于API的认证。
gin中提供了router.Group这一方法,可以对Router的某一URL进行多个操作,例如绑定Middleware和绑定Handler。可以先用router.Group获取到一个RouterGroup,然后用group.Use绑定一个Middleware。
Middleware的实现是一个接受一个*gin.Context类型的参数的函数。在这个函数中,你可以分析请求,如果需要拒绝请求,使用context.Abort方法,如果请求可以继续处理,使用context.Next方法。以下是一个使用Middleware对API做简单验证的例子。
type ReqType struct {
var Pass int `json:"pass"`
}
func main() {
router := gin.Default()
api := router.Group("/api")
api.Use(func(context *gin.Context) {
var req ReqType
err := context.BindJSON(&req)
if err != nil || req.Pass != "password" {
context.JSON(http.StatusUnauthorized, gin.H{
"error": "error!",
})
context.Abort()
return
}
context.Next()
})
api.POST("/", func(context *gin.Context) {
context.JSON(http.StatusOK, gin.H{
"message": "welcome",
})
})
_ = router.Run()
}Copyright © 2017-2022 KSkun's Blog.
Authored by KSkun and his friends.

本博客内所有原创内容采用知识共享署名-相同方式共享 4.0 国际许可协议进行许可。引用内容如果侵权,请在此留言。
All original content in this blog is licensed under a Creative Commons Attribution-ShareAlike 4.0 International License.
If any reference content infringes your rights, please contact us.
![[CSP-S2 2019]树上的数 题解](https://ksmeow.moe/wp-content/uploads/2019/11/shirobako1-14-760x400.jpg)

![[CSP-S2 2019]格雷码 题解](https://ksmeow.moe/wp-content/uploads/2019/11/shirobako1-12-1-760x400.jpg)


