![[BZOJ3685]普通van Emde Boas树 题解](https://ksmeow.moe/wp-content/uploads/2018/07/180703b.jpg)
[BZOJ3685]普通van Emde Boas树 题解
题目地址:BZOJ:Problem 3685. — 普通van Emde Bo …
May all the beauty be blessed.
![[CF916E]Jamie and Tree 题解](https://ksmeow.moe/wp-content/uploads/2018/06/180620a.jpg)
题目地址:Codeforces:Problem – 916E – Codeforces、洛谷:【CF916E】Jamie and Tree – 洛谷
To your surprise, Jamie is the final boss! Ehehehe.
Jamie has given you a tree with n vertices, numbered from 1 to n. Initially, the root of the tree is the vertex with number 1. Also, each vertex has a value on it.
Jamie also gives you three types of queries on the tree:
1 v — Change the tree’s root to vertex with number v.
2 u v x — For each vertex in the subtree of smallest size that contains u and v, add x to its value.
3 v — Find sum of values of vertices in the subtree of vertex with number v.
A subtree of vertex v is a set of vertices such that v lies on shortest path from this vertex to root of the tree. Pay attention that subtree of a vertex can change after changing the tree’s root.
Show your strength in programming to Jamie by performing the queries accurately!
给你一棵有根树,最开始根是1,点上有点权,三种操作:
输入格式:
The first line of input contains two space-separated integers n and q (1 ≤ n ≤ 10^5, 1 ≤ q ≤ 10^5) — the number of vertices in the tree and the number of queries to process respectively.
The second line contains n space-separated integers a1, a2, …, an ( - 10^8 ≤ ai ≤ 10^8) — initial values of the vertices.
Next n - 1 lines contains two space-separated integers ui, vi (1 ≤ ui, vi ≤ n) describing edge between vertices ui and vi in the tree.
The following q lines describe the queries.
Each query has one of following formats depending on its type:
1 v (1 ≤ v ≤ n) for queries of the first type.
2 u v x (1 ≤ u, v ≤ n, - 10^8 ≤ x ≤ 10^8) for queries of the second type.
3 v (1 ≤ v ≤ n) for queries of the third type.
All numbers in queries’ descriptions are integers.
The queries must be carried out in the given order. It is guaranteed that the tree is valid.
输出格式:
For each query of the third type, output the required answer. It is guaranteed that at least one query of the third type is given by Jamie.
输入样例#1:
6 7 1 4 2 8 5 7 1 2 3 1 4 3 4 5 3 6 3 1 2 4 6 3 3 4 1 6 2 2 4 -5 1 4 3 3
输出样例#1:
27 19 5
输入样例#2:
4 6 4 3 5 6 1 2 2 3 3 4 3 1 1 3 2 2 4 3 1 1 2 2 4 -3 3 1
输出样例#2:
18 21
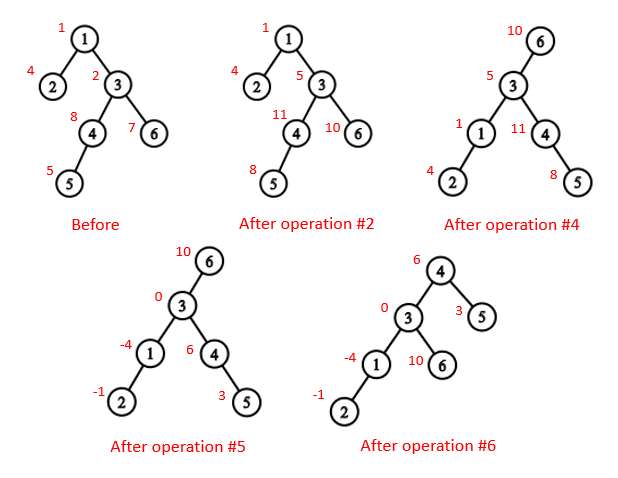
The following picture shows how the tree varies after the queries in the first sample.
雅礼集训Day 1 Prob 1,然而并没能A掉。
换根用LCT做比较快,而子树和用DFS序线段树做比较快。我们要从里面选择一种方法实现。
LCT做的话,需要用到维护子树(包含虚边连的子树)信息的LCT,还要用LCT实现找LCA的算法。具体做法是,找access u和access v路径上最深的相同点。
用线段树做会好写一些,换根对子树加法求和的影响实际上可以讨论出来。试想一条现在根(即1)到换根后的根的路径,对于子树加法的操作,如果u到v的路径与当前根到1的路径无交集时,换根对它产生不了影响,例如样例1中,换根到6后的u=4, v=5这个点对就属于该种情况,这种情况的判定是u和v在根为1的树(下称原树)的LCA与现在的根再求一次LCA,若得到的结果不是原来的LCA,说明属于此种情况;反之,我们需要找到两条路径交集中最深的那个点,可以在LCA(u, rt)和LCA(v, rt)中取最深点,这个点在换根后的树上是最浅的点,子树加法时,只需要加这个点上面的那部分即可,即全树加x,再在当前根到1的路径上的这个点的子节点对应的子树处-x即可,查询同理加全树减这一部分权值即可。
需要保证操作是严格$O(\log n)$的否则会被卡,复杂度$O(n \log n)$。
// Code by KSkun, 2018/6
#include <cstdio>
#include <cctype>
#include <algorithm>
#include <vector>
typedef long long LL;
inline char fgc() {
static char buf[100000], *p1 = buf, *p2 = buf;
return p1 == p2 && (p2 = (p1 = buf) + fread(buf, 1, 100000, stdin), p1 == p2)
? EOF : *p1++;
}
inline LL readint() {
register LL res = 0, neg = 1; register char c = fgc();
for(; !isdigit(c); c = fgc()) if(c == '-') neg = -1;
for(; isdigit(c); c = fgc()) res = (res << 1) + (res << 3) + c - '0';
return res * neg;
}
const int MAXN = 100005;
std::vector<int> gra[MAXN];
int n, q, a[MAXN];
int fa[MAXN], siz[MAXN], son[MAXN], dep[MAXN];
inline void dfs1(int u) {
siz[u] = 1;
for(int i = 0; i < gra[u].size(); i++) {
int v = gra[u][i];
if(v == fa[u]) continue;
fa[v] = u; dep[v] = dep[u] + 1;
dfs1(v); siz[u] += siz[v];
if(siz[v] > siz[son[u]]) son[u] = v;
}
}
int top[MAXN], dfn[MAXN], vn[MAXN], clk;
inline void dfs2(int u, int tp) {
dfn[u] = ++clk; vn[dfn[u]] = u; top[u] = tp;
if(son[u]) dfs2(son[u], tp);
for(int i = 0; i < gra[u].size(); i++) {
int v = gra[u][i];
if(v == fa[u] || v == son[u]) continue;
dfs2(v, v);
}
}
inline int querylca(int u, int v) {
int tu = top[u], tv = top[v];
while(tu != tv) {
if(dep[tu] > dep[tv]) {
std::swap(u, v); std::swap(tu, tv);
}
v = fa[tv]; tv = top[v];
}
if(dep[u] < dep[v]) return u; else return v;
}
LL sum[MAXN << 2], tag[MAXN << 2];
#define lch o << 1
#define rch o << 1 | 1
#define mid ((l + r) >> 1)
inline void build(int o, int l, int r) {
if(l == r) {
sum[o] = a[vn[l]]; return;
}
build(lch, l, mid);
build(rch, mid + 1, r);
sum[o] = sum[lch] + sum[rch];
}
inline void pushdown(int o, int l, int r) {
if(tag[o]) {
tag[lch] += tag[o]; tag[rch] += tag[o];
sum[lch] += tag[o] * (mid - l + 1); sum[rch] += tag[o] * (r - mid);
tag[o] = 0;
}
}
inline void add(int o, int l, int r, int ll, int rr, LL v) {
if(l >= ll && r <= rr) {
sum[o] += v * (r - l + 1); tag[o] += v; return;
}
pushdown(o, l, r);
if(ll <= mid) add(lch, l, mid, ll, rr, v);
if(rr > mid) add(rch, mid + 1, r, ll, rr, v);
sum[o] = sum[lch] + sum[rch];
}
inline LL query(int o, int l, int r, int ll, int rr) {
if(l >= ll && r <= rr) return sum[o];
pushdown(o, l, r); LL res = 0;
if(ll <= mid) res += query(lch, l, mid, ll, rr);
if(rr > mid) res += query(rch, mid + 1, r, ll, rr);
return res;
}
int rt = 1;
int main() {
n = readint(); q = readint();
for(int i = 1; i <= n; i++) {
a[i] = readint();
}
for(int i = 1, u, v; i < n; i++) {
u = readint(); v = readint();
gra[u].push_back(v); gra[v].push_back(u);
}
dfs1(1); dfs2(1, 1); build(1, 1, n);
while(q--) {
int op, u, v, x;
op = readint();
if(op == 1) {
rt = readint();
} else if(op == 2) {
u = readint(); v = readint(); x = readint();
int lca = querylca(u, v), l1 = querylca(u, rt), l2 = querylca(v, rt);
if(rt == 1 || querylca(lca, rt) != lca) {
add(1, 1, n, dfn[lca], dfn[lca] + siz[lca] - 1, x);
} else {
lca = dep[l1] > dep[l2] ? l1 : l2;
add(1, 1, n, 1, n, x);
if(lca != rt) {
int p = rt;
while(dep[fa[top[p]]] > dep[lca]) p = fa[top[p]];
p = vn[dfn[p] - (dep[p] - dep[lca] - 1)];
add(1, 1, n, dfn[p], dfn[p] + siz[p] - 1, -x);
}
}
} else {
u = readint();
if(rt == 1 || querylca(u, rt) != u) {
printf("%lld\n", query(1, 1, n, dfn[u], dfn[u] + siz[u] - 1));
} else {
LL res = 0;
res += query(1, 1, n, 1, n);
if(u != rt) {
int p = rt;
while(dep[fa[top[p]]] > dep[u]) p = fa[top[p]];
p = vn[dfn[p] - (dep[p] - dep[u] - 1)];
res -= query(1, 1, n, dfn[p], dfn[p] + siz[p] - 1);
}
printf("%lld\n", res);
}
}
}
return 0;
}
![[BZOJ3551][ONTAK2010]Peaks加强版 题解](https://ksmeow.moe/wp-content/uploads/2018/06/180614b.jpg)
题目地址:BZOJ:Problem 3551. — [ONTAK2010]Peaks加强版
在Bytemountains有N座山峰,每座山峰有他的高度h_i。有些山峰之间有双向道路相连,共M条路径,每条路径有一个困难值,这个值越大表示越难走,现在有Q组询问,每组询问询问从点v开始只经过困难值小于等于x的路径所能到达的山峰中第k高的山峰,如果无解输出-1。
有一个图,点和边都有权值。回答若干询问,每个询问表示只保留图中边权不大于x的边,v所在的连通块中,点权k大。强制在线。
输入格式:
第一行三个数N,M,Q。
第二行N个数,第i个数为h_i
接下来M行,每行3个数a b c,表示从a到b有一条困难值为c的双向路径。
接下来Q行,每行三个数v x k,表示一组询问。v=v xor lastans,x=x xor lastans,k=k xor lastans。如果lastans=-1则不变。
输出格式:
对于每组询问,输出一个整数表示答案。
输入样例#1:
10 11 4 1 2 3 4 5 6 7 8 9 10 1 4 4 2 5 3 9 8 2 7 8 10 7 1 4 6 7 1 6 4 8 2 1 5 10 8 10 3 4 7 3 4 6 1 5 2 7 3 0 0 4 9 9 8 3
输出样例#1:
6 1 -1 8
【数据范围】
N<=10^5, M,Q<=5*10^5,h_i,c,x<=10^9。
参考资料:BZOJ 3551: [ONTAK2010]Peaks加强版 [Kruskal重构树 dfs序 主席树] – Candy? – 博客园
强制在线之前的离线做法就不行了。这里要用新的科技:Kruskal重构树。
首先,连通块的边肯定在最小生成树上比较优,因此我们可以跑一波Kruskal处理。在Kruskal选中一条边的时候,对这条边开一个点,把边权放在点上,再从点引出两条边,指向边的端点的并查集集合代表元,将这条边的点设为这两个集合的并集代表元。
这样建出来的树有优秀的性质:
这里我们会用到第5条。一个查询就是在找v的边权不大于询问的最浅边点祖先,在该祖先的子树内找k大,这个显然可以DFS序建主席树做。
注意本地开够栈,DFS的规模会相当大。复杂度是O(n \log n)。
// Code by KSkun, 2018/6
#include <cstdio>
#include <cctype>
#include <algorithm>
#include <vector>
typedef long long LL;
inline char fgc() {
static char buf[100000], *p1 = buf, *p2 = buf;
return p1 == p2 && (p2 = (p1 = buf) + fread(buf, 1, 100000, stdin), p1 == p2)
? EOF : *p1++;
}
inline LL readint() {
register LL res = 0, neg = 1; register char c = fgc();
for(; !isdigit(c); c = fgc()) if(c == '-') neg = -1;
for(; isdigit(c); c = fgc()) res = (res << 1) + (res << 3) + c - '0';
return res * neg;
}
const int MAXN = 200005, MAXM = 500005;
int n, m, q, N;
int fa[MAXN];
inline int find(int x) {
return x == fa[x] ? x : fa[x] = find(fa[x]);
}
struct Node {
int lch, rch, val;
} tr[MAXN << 4];
int rt[MAXN], tot;
inline void insert(int &o, int l, int r, int x) {
tr[++tot] = tr[o]; o = tot;
tr[o].val++;
if(l == r) return;
int mid = (l + r) >> 1;
if(x <= mid) insert(tr[o].lch, l, mid, x);
else insert(tr[o].rch, mid + 1, r, x);
}
inline int query(int o1, int o2, int l, int r, int k) {
if(l == r) return l;
int mid = (l + r) >> 1, rsiz = tr[tr[o2].rch].val - tr[tr[o1].rch].val;
if(k <= rsiz) return query(tr[o1].rch, tr[o2].rch, mid + 1, r, k);
else return query(tr[o1].lch, tr[o2].lch, l, mid, k - rsiz);
}
int w[MAXN], anc[MAXN][20];
std::vector<int> gra[MAXN];
struct Edge {
int u, v, w;
} edges[MAXM];
inline bool cmp(Edge a, Edge b) {
return a.w < b.w;
}
inline void kruskal() {
int cnt = 0;
for(int i = 1; i <= m; i++) {
int u = edges[i].u, v = edges[i].v, fu = find(u), fv = find(v);
if(fu == fv) continue;
w[++N] = edges[i].w;
gra[N].push_back(fu); gra[N].push_back(fv);
fa[fu] = fa[fv] = fa[N] = N;
if(++cnt == n - 1) break;
}
}
int vn[MAXN], dep[MAXN], dfl[MAXN], dfr[MAXN], clk;
inline void dfs(int u) {
dfl[u] = clk;
if(u <= n) vn[++clk] = u;
for(int i = 1; (1 << i) <= dep[u]; i++) {
anc[u][i] = anc[anc[u][i - 1]][i - 1];
}
for(int i = 0; i < gra[u].size(); i++) {
int v = gra[u][i];
if(v == anc[u][0]) continue;
dep[v] = dep[u] + 1;
anc[v][0] = u;
dfs(v);
}
dfr[u] = clk;
}
inline int findrt(int u, int x) {
for(int i = 19; i >= 0; i--) {
if(anc[u][i] && w[anc[u][i]] <= x) u = anc[u][i];
}
return u;
}
std::vector<int> tmp;
int main() {
n = readint(); m = readint(); q = readint(); N = n;
for(int i = 1; i <= n; i++) {
fa[i] = i;
}
tmp.push_back(-1);
for(int i = 1; i <= n; i++) {
w[i] = readint();
tmp.push_back(w[i]);
}
for(int i = 1; i <= m; i++) {
edges[i].u = readint(); edges[i].v = readint(); edges[i].w = readint();
}
std::sort(edges + 1, edges + m + 1, cmp);
kruskal();
dfs(N);
std::sort(tmp.begin(), tmp.end());
tmp.erase(std::unique(tmp.begin(), tmp.end()), tmp.end());
for(int i = 1; i <= n; i++) {
w[i] = std::lower_bound(tmp.begin(), tmp.end(), w[i]) - tmp.begin();
}
for(int i = 1; i <= n; i++) {
rt[i] = rt[i - 1];
insert(rt[i], 1, n, w[vn[i]]);
}
int lastans = 0, v, x, k;
while(q--) {
v = readint() ^ lastans; x = readint() ^ lastans; k = readint() ^ lastans;
v = findrt(v, x);
if(tr[rt[dfr[v]]].val - tr[rt[dfl[v]]].val < k) puts("-1"), lastans = 0;
else printf("%d\n", lastans = tmp[query(rt[dfl[v]], rt[dfr[v]], 1, n, k)]);
}
return 0;
}
![[BZOJ3439]Kpm的MC密码 题解](https://ksmeow.moe/wp-content/uploads/2018/06/180613a.jpg)
题目地址:BZOJ:Problem 3439. — Kpm的MC密码
Kpm当年设下的问题是这样的:
现在定义这么一个概念,如果字符串s是字符串c的一个后缀,那么我们称c是s的一个kpm串。
系统将随机生成n个由a…z组成的字符串,由1…n编号(s1,s2…,sn),然后将它们按序告诉你,接下来会给你n个数字,分别为k1…kn,对于每一个ki,要求你求出列出的n个字符串中所有是si的kpm串的字符串的编号中第ki小的数,如果不存在第ki小的数,则用-1代替。(比如说给出的字符串是cd,abcd,bcd,此时k1=2,那么”cd”的kpm串有”cd”,”abcd”,”bcd”,编号分别为1,2,3其中第2小的编号就是2)(PS:如果你能在相当快的时间里回答完所有n个ki的查询,那么你就可以成功帮kpm进入MC啦~~)
给n个字符串,按1~n编号。对于每一个字符串s,询问s是后缀的字符串中,编号第k大的编号。
输入格式:
第一行一个整数 n 表示字符串的数目
接下来第二行到n+1行总共n行,每行包括一个字符串,第i+1行的字符串表示编号为i的字符串
接下来包括n行,每行包括一个整数ki,意义如上题所示
输出格式:
包括n行,第i行包括一个整数,表示所有是si的kpm串的字符串的编号中第ki小的数
输入样例#1:
3 cd abcd bcd 2 3 1
输出样例#1:
2 -1 2
样例解释
“cd”的kpm 串有”cd”,”abcd”,”bcd”,编号为1,2,3,第2小的编号是2,”abcd”的kpm串只有一个,所以第3小的编号不存在,”bcd”的kpm串有”abcd”,”bcd”,第1小的编号就是2。
数据范围与约定
对于100%的数据,1<=n<=100000
要查后缀是某串的字符串有哪些,自然可以想到反着插入Trie树,找该串末结点对应的子树中的结尾标记。既然是子树查询k大,我们可以按DFS序建主席树来查。
复杂度O(n \log n)。
// Code by KSkun, 2018/6
#include <cstdio>
#include <cctype>
#include <cstring>
#include <algorithm>
typedef long long LL;
inline char fgc() {
static char buf[100000], *p1 = buf, *p2 = buf;
return p1 == p2 && (p2 = (p1 = buf) + fread(buf, 1, 100000, stdin), p1 == p2)
? EOF : *p1++;
}
inline LL readint() {
register LL res = 0, neg = 1; register char c = fgc();
for(; !isdigit(c); c = fgc()) if(c == '-') neg = -1;
for(; isdigit(c); c = fgc()) res = (res << 1) + (res << 3) + c - '0';
return res * neg;
}
const int MAXN = 100005;
int ch[MAXN][26], ed[MAXN], tot;
int head[MAXN], val[MAXN], nxt[MAXN], ltot;
inline void insert(char *str, int id) {
int n = strlen(str + 1), p = 0;
for(int i = n; i >= 1; i--) {
int t = str[i] - 'a';
if(!ch[p][t]) ch[p][t] = ++tot;
p = ch[p][t];
}
val[++ltot] = id; nxt[ltot] = head[p]; head[p] = ltot; ed[id] = p;
}
int dfn[MAXN], vn[MAXN], siz[MAXN], clk;
inline void dfs(int u) {
dfn[u] = ++clk; vn[dfn[u]] = u;
siz[u] = 1;
for(int i = 0; i < 26; i++) {
if(ch[u][i]) {
dfs(ch[u][i]); siz[u] += siz[ch[u][i]];
}
}
}
struct Node {
int lch, rch, val, id;
} tr[MAXN << 4];
int rt[MAXN], stot;
inline void insert(int &o, int l, int r, int x, int id) {
if(tr[o].id != id) {
tr[++stot] = tr[o]; o = stot; tr[o].id = id;
}
tr[o].val++;
if(l == r) return;
int mid = (l + r) >> 1;
if(x <= mid) insert(tr[o].lch, l, mid, x, id);
else insert(tr[o].rch, mid + 1, r, x, id);
}
inline int query(int o1, int o2, int l, int r, int k) {
if(l == r) return l;
int mid = (l + r) >> 1, lsiz = tr[tr[o2].lch].val - tr[tr[o1].lch].val;
if(k <= lsiz) return query(tr[o1].lch, tr[o2].lch, l, mid, k);
else return query(tr[o1].rch, tr[o2].rch, mid + 1, r, k - lsiz);
}
int n, k;
char s[MAXN];
int main() {
scanf("%d", &n);
for(int i = 1; i <= n; i++) {
scanf("%s", s + 1);
insert(s, i);
}
dfs(0);
for(int i = 1; i <= clk; i++) {
rt[i] = rt[i - 1];
for(int j = head[vn[i]]; j; j = nxt[j]) {
insert(rt[i], 1, n, val[j], i);
}
}
for(int i = 1; i <= n; i++) {
scanf("%d", &k);
if(tr[rt[dfn[ed[i]] + siz[ed[i]] - 1]].val - tr[rt[dfn[ed[i]] - 1]].val < k) {
puts("-1"); continue;
}
printf("%d\n", query(rt[dfn[ed[i]] - 1], rt[dfn[ed[i]] + siz[ed[i]] - 1], 1, n, k));
}
return 0;
}
Copyright © 2017-2022 KSkun's Blog.
Authored by KSkun and his friends.

本博客内所有原创内容采用知识共享署名-相同方式共享 4.0 国际许可协议进行许可。引用内容如果侵权,请在此留言。
All original content in this blog is licensed under a Creative Commons Attribution-ShareAlike 4.0 International License.
If any reference content infringes your rights, please contact us.
![[ZJOI2009]对称的正方形 题解](https://ksmeow.moe/wp-content/uploads/2018/06/180622a.jpg)
![[WC2010]重建计划 题解](https://ksmeow.moe/wp-content/uploads/2018/06/180619a.jpg)
![[BZOJ3091]城市旅行 题解](https://ksmeow.moe/wp-content/uploads/2018/06/180617a.jpg)
![[ONTAK2010]Peaks 题解](https://ksmeow.moe/wp-content/uploads/2018/06/180614a.jpg)
![[POI2003]Monkeys 题解](https://ksmeow.moe/wp-content/uploads/2018/06/180613d.jpg)
![[SPOJ-GSS4]Can you answer these queries IV 题解](https://ksmeow.moe/wp-content/uploads/2018/06/180611c.jpg)