![[CF7D]Palindrome Degree 题解](https://ksmeow.moe/wp-content/uploads/2019/08/shirobako1-8-720x400.jpg)
[CF7D]Palindrome Degree 题解
题目地址:Codeforces:Problem – 7D – Co …
May all the beauty be blessed.
![[TJOI2015]弦论 题解](https://ksmeow.moe/wp-content/uploads/2018/07/180717a.jpg)
题目地址:洛谷:【P3975】[TJOI2015]弦论 – 洛谷、BZOJ:Problem 3998. — [TJOI2015]弦论
为了提高智商,ZJY开始学习弦论。这一天,她在《 String theory》中看到了这样一道问题:对于一个给定的长度为n的字符串,求出它的第k小子串是什么。你能帮帮她吗?
求一个串的本质不同子串中第k小或所有子串中第k小。
输入格式:
第一行是一个仅由小写英文字母构成的字符串s
第二行为两个整数t和k,t为0则表示不同位置的相同子串算作一个,t为1则表示不同位置的相同子串算作多个。k的意义见题目描述。
输出格式:
输出数据仅有一行,该行有一个字符串,为第k小的子串。若子串数目不足k个,则输出-1。
输入样例#1:
aabc 0 3
输出样例#1:
aab
输入样例#2:
aabc 1 3
输出样例#2:
aa
输入样例#3:
aabc 1 11
输出样例#3:
-1
数据范围
对于10%的数据,n ≤ 1000。
对于50%的数据,t = 0。
对于100%的数据,n ≤ 5 × 10^5, t < 2, k ≤ 10^9。
对于SAM来说,这个题是一种经典应用了。
在DAWG上的任何一条从起点出发的路径都是原串的一个子串,因此,如果我们能求出经过一个点的路径数(即DAWG上它能到达的点的数量)就可以知道某一个点的“子树”(由于DAWG并不是严格的树,因此采用这种称呼)中可以表示多少串,从起始点开始往深走就可以求出答案。
对于本质不同的情况,只需把起点到这个点的路径数设置为1,求这个值的“子树和”即可,对于考虑重复的情况,上述值设置为$\mathrm{endpos}$集合大小即可。求和可以用拓扑序($\max$从大到小的顺序)处理。
这里用了std::sort因此复杂度$O(n \log n)$。
// Code by KSkun, 2018/7
#include <cstdio>
#include <cctype>
#include <cstring>
#include <algorithm>
#include <vector>
#include <stack>
#include <set>
typedef long long LL;
inline char fgc() {
static char buf[100000], *p1 = buf, *p2 = buf;
return p1 == p2 && (p2 = (p1 = buf) + fread(buf, 1, 100000, stdin), p1 == p2)
? EOF : *p1++;
}
inline LL readint() {
register LL res = 0, neg = 1; register char c = fgc();
for(; !isdigit(c); c = fgc()) if(c == '-') neg = -1;
for(; isdigit(c); c = fgc()) res = res * 10 + c - '0';
return res * neg;
}
const int MAXN = 1000005;
struct SuffixAutomaton {
int ch[MAXN][26], len[MAXN], nxt[MAXN], siz[MAXN], lst, tot;
SuffixAutomaton() {
lst = tot = 1;
}
inline void extend(int c) {
int u = ++tot, v = lst;
len[u] = len[v] + 1;
for(; v && !ch[v][c]; v = nxt[v]) ch[v][c] = u;
if(!v) {
nxt[u] = 1;
} else if(len[ch[v][c]] == len[v] + 1) {
nxt[u] = ch[v][c];
} else {
int o = ch[v][c], n = ++tot;
memcpy(ch[n], ch[o], sizeof(ch[o]));
len[n] = len[v] + 1;
for(; v && ch[v][c] == o; v = nxt[v]) ch[v][c] = n;
nxt[n] = nxt[o]; nxt[o] = nxt[u] = n;
}
lst = u; siz[lst] = 1;
}
} sam;
inline bool cmp(int a, int b) {
return sam.len[a] > sam.len[b];
}
int n, t, k, a[MAXN], sum[MAXN];
char s[MAXN];
int main() {
scanf("%s%d%d", s + 1, &t, &k);
n = strlen(s + 1);
for(int i = 1; i <= n; i++) {
sam.extend(s[i] - 'a');
}
for(int i = 1; i <= sam.tot; i++) {
a[i] = i;
}
std::sort(a + 1, a + sam.tot + 1, cmp);
for(int i = 1; i <= sam.tot; i++) {
if(t) sam.siz[sam.nxt[a[i]]] += sam.siz[a[i]];
else sam.siz[a[i]] = 1;
}
sam.siz[1] = 0;
for(int i = 1; i <= sam.tot; i++) {
sum[a[i]] = sam.siz[a[i]];
for(int j = 0; j < 26; j++) {
if(sam.ch[a[i]][j]) sum[a[i]] += sum[sam.ch[a[i]][j]];
}
}
if(k > sum[1]) {
puts("-1"); return 0;
}
int p = 1;
while(k - sam.siz[p] > 0) {
k -= sam.siz[p];
int q = 0;
while(k > sum[sam.ch[p][q]]) k -= sum[sam.ch[p][q++]];
p = sam.ch[p][q];
putchar('a' + q);
}
return 0;
}

回文自动机(简称PAM,又称回文树,Palindromic Tree)是一种用于处理回文串的结构,在其结构内可以找到原串中的所有回文子串,经由APIO2014推广。下面对其原理及实现进行介绍。
本文中所有图片来自网络,感谢其作者的贡献。
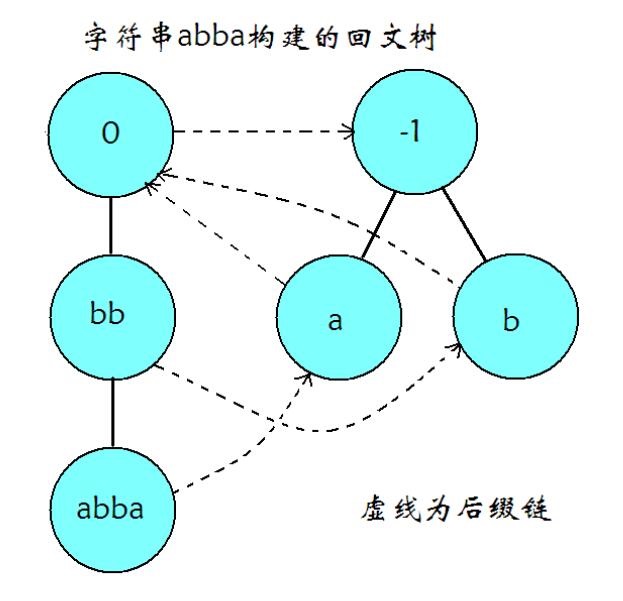
如图为串abba的PAM示意图,其中,实现表示回文串的扩展转移边,虚线表示后缀链接。
回文树是PAM的一部分,一个PAM包含两棵回文树,分别代表奇偶回文串。每棵回文树上,所有节点(除树根以外)都代表了一个回文子串。每条转移边上都有一个字符,若某点对应的回文子串为$S$,它的一条出边上字符为$c$,则会转移至一个代表$c+S+c$串的节点。从树根出发的每条路径,都对应着一个回文子串,如果将路径上边的字符顺次连接,将会得到回文串的右半部分。
abba的PAM中,节点$u$代表串bb,节点$v$代表串abba,存在$u \rightarrow v$的转移边,$\mathrm{len}(u)=2$且$\mathrm{len}(v)=4$。转移边$u \rightarrow v$对节点的意义是,将$u$对应的回文串左右两边加上同一个字符$c$得到节点$v$对应的回文串。由于$u$对应的回文串是$v$对应的回文串的子串,因此,$v$对应的回文串出现的地方,$u$对应的回文串也出现了。
abba的PAM,对应abba的节点$u$与对应a的节点$v$,存在$\mathrm{fail}(u)=v$。PAM的构造法在字符集为常数且较小时,是线性复杂度的。与SAM相似的是,PAM的构造法也是一个增量算法,因此,应该解释为,每次在母串后插入一个字符,更新PAM的复杂度是$O(1)$的。
PAM中,我们需要记下上一次插入的节点位置,即$lst$。
下面,我们结合例子解释插入的过程。
如图,为串abba的PAM,我们向其插入新字符a。
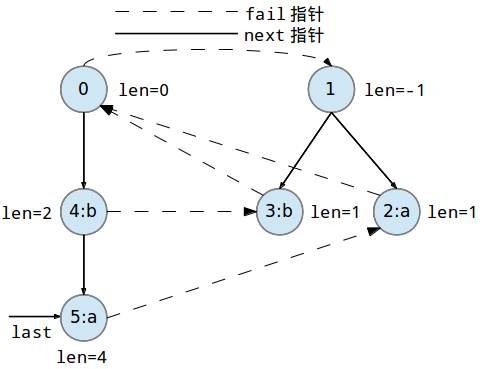
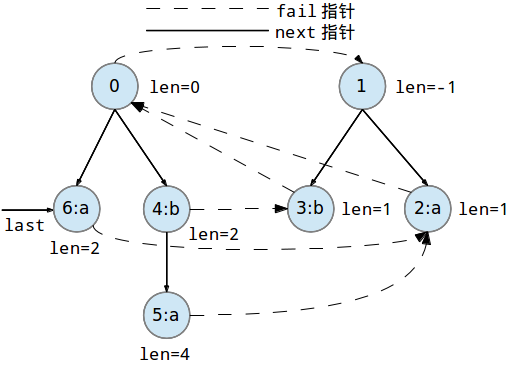
abba后加入字符a构成的新串是abbaa,这一过程实际上是找到一个新串的一个最长回文后缀,也就是aa的父节点,我们找到的是偶回文树的树根$0$。aa回文串的最长回文后缀是a,容易发现,从父节点$0$开始上跳,会跳到奇回文树根$1$,从而找到对应的最长回文后缀节点$2$,即对于新加点$u=6$,有$\mathrm{fail}(6)=2$。经过上面一通处理,现在,PAM的结构变为了下图的样子。
参见例题。
点击标题进入文章。
即后缀树中节点的数量。
先按逆序(拓扑序)更新父节点$\mathrm{siz}(u)$值然后就可以直接拿来用了。

后缀自动机(Suffix Automaton,简称SAM)是一种用于字符串处理的有限状态自动机(DFA),它可以接受其母串的任何一个后缀,且构造算法为线性算法。下面对其原理及实现进行介绍。
本文中所有SAM示意图皆为SAM Builder生成的图片,构造法处略图来自Menci博客。本文部分内容有摘录参考资料或摘录并改编的部分,参考资料均已附链接。

如图为串abc的SAM示意图,其中,实线黑色箭头表示节点的转移边,虚线蓝色箭头表示后缀链接。
DAWG是SAM的一部分,对于一个DAWG,每个节点(除起始节点外)都可以代表一个或多个子串(的结束点),每条转移边上都有一个字符,从起始节点沿转移边走,每条路径都对应一个子串,即路径上所有边的字符相连构成的。
SAM是一个DFA,它可以接受一些字符串,可以接受的字符串是指从起始节点开始,沿着每一个字符对应的转移边在DAWG上转移,最后到达某个节点的字符串。显然,可以接受的字符串一定是母串的一个子串。而如果这个字符串是母串的一个后缀,则称它的终止节点为可接受的节点。
abcabcabc,它的一个前缀是abcab,某个节点所表示的子串可能是cab、bcab、abcab。abcabcabc,某个节点$v$所表示的子串可能是cab、bcab、abcab,因此,$\min(v) = \mathtt{cab}, \max(v) = \mathtt{abcab}$。abcabcabc,某个节点$v$所表示的子串可能是cab、bcab、abcab,因此,$\mathrm{endpos}(v) = \{ 5, 8 \}$。节点$u$到$v$有转移边,表示$u$代表的所有子串加上转移边对应的字符后,得到的集合是$v$代表的子串集合的子集,但是,并不保证两个集合相等。
abcabcabc,一个节点$u$可能代表子串abca、bca、ca,一个节点$v$可能代表子串a,则存在后缀链接$\mathrm{next}(u)=v$。在字符集为常数且较小时,SAM的构造法为线性复杂度的。这是一个增量算法,因此,实际上应该解释为,每在母串后插入一个字符,更新SAM的复杂度是$O(1)$的。
这里,我们将主要使用略图结合实际例子的形式描述增量过程。

上图描述了一个串的SAM略图,我们要在这个串末尾加上字符$c$,图中,灰色的边表示字符$c$的转移边,黑色的边表示后缀链接,$\text{start}$为起始节点$\text{last}$为代表整个母串的节点。





到这里,算法的流程就结束了,下面我们用若干个例子来加深理解。
abc中加入aabc的SAM结构 | abca的SAM结构 |
|---|---|
对于这个串,从代表母串的节点4上跳到第一个有字符a出边的节点即是起始节点1,因此节点4需要在下面新建节点5代表新后缀abca,并将节点5的后缀链接指向节点2,即节点1的a出边对应的节点,这是由于$len_2 = len_1 + 1$。在图中,$len$指的就是$|\max|$。
abca中加入cabca的SAM结构 | abca的SAM结构 |
|---|---|
首先从结尾节点5上跳,节点5、2没有字符c的出边,因此新建节点6来代表新后缀abcac与ac。节点1有字符c的出边,对应节点4,但是$len_4 \neq len_1 + 1$,因此需要对4拆点,新点为7,继承了4的出边,且从4上跳前缀树路径上所有指向4的边都应改为指向7。此时,6和4的后缀链接指向7,7继承了原来4的后缀链接指向1,完成构造。
实现可以参考后文例题中的代码。
实现中,只需记下每个节点的$|\max|$即可,因为$|\min(u)| = |\max(\mathrm{next}(u))| + 1$。
给定一个只包含小写字母的字符串 S ,请你求出 S 的所有出现次数不为 1 的子串的出现次数乘上该子串长度的最大值。
出现次数不为1的子串,可以求出每个节点的$\mathrm{endpos}$集合大小,即上文中提到的,从前缀树的子节点加和,这个过程可以使用拓扑序来做。由于我们知道前缀树的节点越深$|\max|$越大,因此可以对这个值排序后直接转移统计。对于每个$\mathrm{endpos}$集合大小大于1的节点计算其$|\mathrm{endpos}||\max|$值更新答案即可。
// Code by KSkun, 2018/6
#include <cstdio>
#include <cctype>
#include <cstring>
#include <algorithm>
typedef long long LL;
inline char fgc() {
static char buf[100000], *p1 = buf, *p2 = buf;
return p1 == p2 && (p2 = (p1 = buf) + fread(buf, 1, 100000, stdin), p1 == p2)
? EOF : *p1++;
}
inline LL readint() {
register LL res = 0, neg = 1; register char c = fgc();
for (; !isdigit(c); c = fgc()) if (c == '-') neg = -1;
for (; isdigit(c); c = fgc()) res = (res << 1) + (res << 3) + c - '0';
return res * neg;
}
const int MAXN = 1000005;
struct SuffixAutomaton {
int last, tot, ch[MAXN << 1][26], nxt[MAXN << 1], len[MAXN << 1], siz[MAXN << 1];
SuffixAutomaton() {
last = tot = 1;
}
inline void extend(int c) {
int u = ++tot, v = last;
len[u] = len[v] + 1;
for(; v && !ch[v][c]; v = nxt[v]) ch[v][c] = u;
if(!v) {
nxt[u] = 1;
} else if(len[ch[v][c]] == len[v] + 1) {
nxt[u] = ch[v][c];
} else {
int n = ++tot, o = ch[v][c]; len[n] = len[v] + 1;
memcpy(ch[n], ch[o], sizeof(ch[o]));
nxt[n] = nxt[o]; nxt[o] = nxt[u] = n;
for(; v && ch[v][c] == o; v = nxt[v]) ch[v][c] = n;
}
last = u; siz[u] = 1;
}
} sam;
char str[MAXN];
int a[MAXN << 1], c[MAXN << 1];
int main() {
scanf("%s", str + 1);
for(int i = 1; str[i]; i++) {
sam.extend(str[i] - 'a');
}
LL ans = 0;
for(int i = 1; i <= sam.tot; i++) c[sam.len[i]]++;
for(int i = 1; i <= sam.tot; i++) c[i] += c[i - 1];
for(int i = 1; i <= sam.tot; i++) a[c[sam.len[i]]--] = i;
for(int i = sam.tot; i; i--) {
int p = a[i];
sam.siz[sam.nxt[p]] += sam.siz[p];
if(sam.siz[p] > 1) ans = std::max(ans, 1ll * sam.siz[p] * sam.len[p]);
}
printf("%lld", ans);
return 0;
}
可以用一个map<int, int>来代替二维数组ch,这样,构造算法的复杂度就会变为$O(n \log n)$。
在例题中提到了,按照$|\max|$从大到小排序可以得到前缀树的拓扑序。这个排序可以使用计数排序,实现线性复杂度。
每个节点$u$表示的字符串长度在$[|\min(u)|, |\max(u)|]$范围内,而且每个节点代表的字符串又各不相同,因此对$\max(u)-\min(u)+1$求和即可。
对于字符串$S$,它的最小表示定义为,将$S$的一个前缀切去并连接在末尾,这样得到的字典序最小的字符串。
求最小表示可以先对$S+S$建立SAM,并从起始节点开始,每次沿着存在的最小字符转移边走,走$|S|$步后,路径对应的字符串即为最小表示。
对其中一个字符串建SAM,记录一个当前匹配的长度$L$和当前走到的节点$v$,枚举另一个字符串的每个字符$c$,如果当前节点有$c$的出边,则沿出边走一步,对$L$加1;否则,跳至$\mathrm{next}(v)$,并将$L$重置为$|\max(\mathrm{next}(v))$,再次检查是否有$c$的出边,做出选择即可。
Copyright © 2017-2022 KSkun's Blog.
Authored by KSkun and his friends.

本博客内所有原创内容采用知识共享署名-相同方式共享 4.0 国际许可协议进行许可。引用内容如果侵权,请在此留言。
All original content in this blog is licensed under a Creative Commons Attribution-ShareAlike 4.0 International License.
If any reference content infringes your rights, please contact us.
![[NOI2015]荷马史诗 题解](https://ksmeow.moe/wp-content/uploads/2018/07/180710d.jpg)
![[NOI2011]阿狸的打字机 题解](https://ksmeow.moe/wp-content/uploads/2018/07/180710c.jpg)
![[APIO2014]回文串 题解](https://ksmeow.moe/wp-content/uploads/2018/06/180629a.jpg)
![[ZJOI2009]对称的正方形 题解](https://ksmeow.moe/wp-content/uploads/2018/06/180622a.jpg)
![[SPOJ-LCS2]Longest Common Substring II 题解](https://ksmeow.moe/wp-content/uploads/2018/06/180617b.jpg)