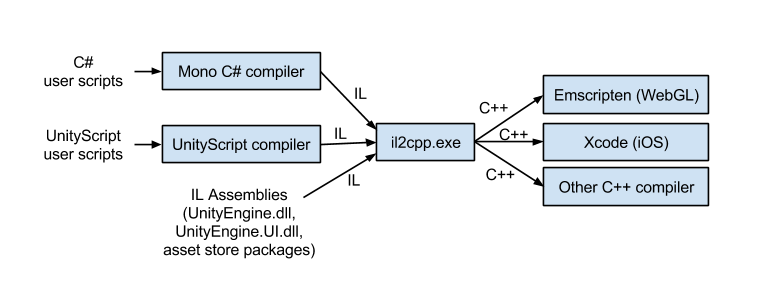
Unity 构建与客户端安全
注:本文是博主在学生团队中所作的一次技术分享。博主本身并非从事构建或安全工作,也并未接触过 …
May all the beauty be blessed.

施工中……现在没有写的部分还有:
虽然没打算写,但有可能会加的部分有:
注:头图来自 GAMES 202 作业 1 任务指导书,文中部分插图来自互联网资料,引用源均在参考资料中列出。

阴影贴图是一种 2-pass 的实时阴影渲染技术。它在阴影 pass 中以光源视角绘制阴影贴图,再在着色 pass 中利用阴影贴图的信息计算直接光照,这个过程类似将阴影生成为贴图,并应用在阴影投射到的物体(receiver)上,故如此称呼。
原始论文:Casting curved shadows on curved surfaces,发布于 SIGGRAPH 1978,作者 Lance Williams (NYIT)。
判断一点是否处于阴影中,即是判断该点和光源的连线上是否存在遮挡物。这可以简单地描述为:从光源的视角能否看到遮挡物,或光源沿此方向看到物体的深度是否小于该点。要得到光源看向场景的深度信息,可以直接使用绘制场景相同的流程,而将绘制结果写入一张深度图(depth map)中即可。在计算直接光时,将该点坐标变换到光源视角中,查询深度图做比较来判断是否被遮挡。因此可以将这一过程分为两个 pass 来实现:
以上为基本流程,但更好的效果需要加入一些修改,详见讨论部分。
如果使用一张 2D 贴图来保存阴影信息,需要选择合适的参数。点光源应选择透视投影,而平行光源应选择正交投影,这关系到投射出阴影的形状是否正确。视锥体应该包含全部场景,远、近平面、视锥边界参数应该取得足够大,否则可能导致深度图查询越界。如果光源没有办法从一个方向看到整个场景,应该考虑生成多张不同角度的深度图,或使用 Cubemap、球形贴图等保存。
此处再整理一下流程中涉及的不同坐标系。在查询深度图时,需要将着色点的世界坐标变换到光源视角的 NDC 坐标下,这通过乘光源的视角变换和投影变换矩阵(V、P 矩阵)实现。NDC 坐标通常在 [-1, 1] 范围内(取决于 API 定义),因此还需要进一步标准化到 [0, 1] 范围,得到深度图上的纹理 UV 坐标。
深度图将标准化深度值保存在贴图像素上,每个像素的颜色值是固定位数的,因此能表示的精度也是有限的,这会为数值带来量化误差。此外,深度图代表遮挡物投影至平面上的结果,但遮挡物不一定与投影平面平行,深度图上的像素实际上代表了与投影平面平行的小面元,这也会带来离散化的误差。

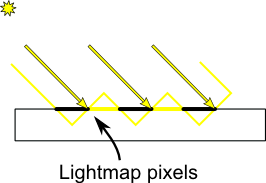
这些误差使得查询深度图的结果可能比真实遮挡物深度偏大或偏小,偏大不会造成严重后果,但偏小可能让遮挡物本身以为自己被遮挡,在没有阴影的地方形成奇怪的暗色斑点、纹路(被称为 Shadow Acne)。可以在判断被遮挡时,在着色点深度加上一个正偏差补偿数值误差,使数值误差不影响遮挡判断结果。
这种误差补偿是有局限性的。当遮挡平面与光源视线成较小角度时,离散化误差将变大,很难补偿这种情况的误差。而阴影遮挡物和被遮挡物离的很近时,被遮挡物的深度又被偏差补偿到小于遮挡物,使得一些阴影没有和遮挡物连起来,看起来好像遮挡物浮空了一样(被称为 Peter Panning)。可以在生成深度图时使用背面剔除,这样可以解决有厚度遮挡物的问题。
由于深度图本身的尺寸有限,阴影投射后放大出现了锯齿状走样。这种走样和渲染中出现的锯齿现象原理类似,可以使用一些采样方法解决。一个方式是 PCF(百分比渐进滤波,Percentage Closer Filter)。着色点映射到深度图上后,不只查询一个像素,而是采样该像素附近一圈像素。采样的范围越大,阴影边缘的过渡部分越宽,锯齿现象越不明显,但阴影边界也会变模糊。
Shadow Mapping 能为实时阴影计算提供遮挡信息,从而方便地实现点光源、平行光源的阴影。然而,光源常常并非二者之一,而是有一定面积的面光源。在面光源下,阴影分为本影(umbra)和半影(penumbra),本影是光源面积完全被遮挡的位置,亮度最暗,而半影是本影周围光源面积部分被遮挡的位置,形成了最暗到最亮的过渡带。半影形成的过渡带使阴影的边缘模糊,形成软阴影(soft shadow)的效果。

PCSS 受到 PCF 滤波效果的启发,通过指定阴影不同位置 PCF 滤波范围大小,来实现类似真实软阴影的效果。这种方法完全基于 Shadow Mapping 的结果,没有额外的前、后处理,也不需要更多信息。
原始论文:Percentage-Closer Soft Shadows,发布于 SIGGRAPH 2005,作者 Randima Fernando (Nvidia)。
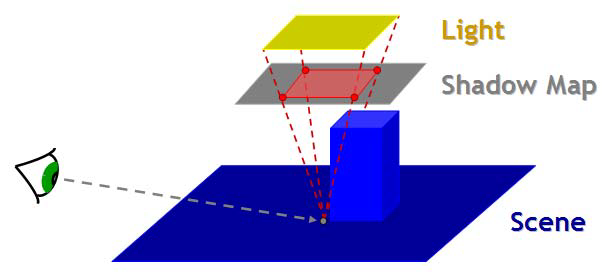
PCSS 通过控制 PCF 滤波范围大小来实现阴影不同程度的软化,因此需要确定着色点处需要选择的 PCF 滤波范围大小,这个大小与光源、遮挡物和被阴影投射物之间的集合关系决定。
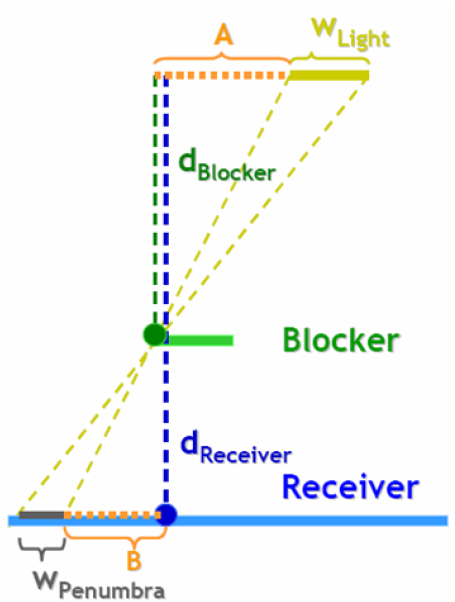
上图所示的场景中,假设光源、遮挡物和投射物平面是平行关系。黄色的线段表示有面积的光源,其宽度为 $w_\text{Light}$,光源被遮挡物(绿色线段)左侧遮挡,其阴影投射在下方的投射物(蓝色线段上),遮挡物到光源距离 $d_\text{Blocker}$,投射物到光源距离 $d_\text{Receiver}$。从光源两端点经遮挡点向投射物连线(黄色虚线),投射物两连线的右方表示两点分别无法照亮的位置,即本影,宽度为 $B$;而两连线之间的部分表示光源被部分遮挡,即半影,宽度为 $w_\text{Penumbra}$。这样就建立了阴影和场景的几何关系。注意到存在一系列相似三角形关系,存在比例
$$ \dfrac{d_\text{Blocker}}{d_\text{Receiver}-d_\text{Blocker}} = \dfrac{w_\text{Light}}{w_\text{Penumbra}} $$
故半影宽度可以由
$$ w_\text{Penumbra} = \dfrac{d_\text{Receiver}-d_\text{Blocker}}{d_\text{Blocker}} \cdot w_\text{Light} $$
求得。另外,此处的两个 $d$ 值可以不是图中的垂线段长度,满足相似三角形的比例关系皆可。
经过上面的讨论,半影宽度与光源大小、遮挡物深度和着色点深度有关,后两个量可以分别从深度图与世界坐标得到,光源大小通常是预定义好的。PCSS 的工作过程可以描述为下面三步:
PCSS 是一种基于 PCF 的很直接的思路,实现的难度也不高。然而由于遮挡物搜索和 PCF 两步中包含两次采样估计过程,PCSS 的效果通常包含许多噪声,需要提高采样数或应用低通滤波等方式改善渲染质量。此外,多次采样会带来大量的贴图查询,带来时间和带宽上的额外开销,效率上依然存在问题。随着时域、空域滤波的技术发展,现在有 TAA 等更好的方法改善 PCSS 的噪声和效率,因此 PCSS 仍然是一种广泛使用的方法。
PCSS 中需要范围查询深度图中的信息来完成遮挡物搜索和 PCF,而范围查询需要通过采样来完成,这会为渲染结果带来采样造成的随机噪声。为了避免这种噪声,有许多方法通过非采样的方法来估计遮挡物的深度。VSSM 是一种利用统计规律来估计遮挡物深度的方法,它基于 Chevbyshev 不等式和方差阴影贴图(VSM,Variance Shadow Mapping)方法,通过使用预计算的信息来避免采样。
原始论文:Variance Soft Shadow Mapping,发布于 PG 2010,作者杨宝光(Autodesk、浙江大学)。
在 PCSS 中,遮挡物的平均深度通过对深度图的采样获得。从这个思路出发,设采样数为 $N$,其中有 $N_1$ 个样本为非遮挡物(深度不小于着色点)、$N_2$ 个样本为遮挡物(深度小于着色点)。记遮挡物的平均深度为 $z_\text{occ}$,非遮挡物的平均深度为 $z_\text{unocc}$,所有样本的平均深度为 $z_\text{Avg}$,则根据平均值的定义可得下面的关系
$$ \dfrac{N_1}{N} z_\text{unocc} + \dfrac{N_2}{N} z_\text{occ} = z_\text{Avg} $$
采样的频率会收敛到概率,故可以用概率来估计样本的频率,此外所有样本的平均深度也可近似为真实的平均深度,则记着色点深度为 $t$,采样的随机变量取值为 $x$,上式可化为
$$ P(x \ge t) z_\text{unocc} + [1 – P(x \ge t)] z_\text{occ} = z_\text{Avg} $$
那么遮挡物的平均深度便可通过下式求出
$$ z_\text{occ} = \dfrac{z_\text{Avg} – P(x \ge t) z_\text{unocc}}{1 – P(x \ge t)} $$
有了这个关系,还需要知道非遮挡物的平均深度 $z_\text{unocc}$,以及实际意义为深度图查询范围中不小于采样点深度的像素占比 $P(x \ge t)$。
对于非遮挡物的深度,一般来说着色点附近的非遮挡物是着色点所在的平面,因此可以近似为着色点的深度 $t$。而遮挡物的占比则可以借助 VSM 的思路解决,对深度图查询范围进行采样,其对应的随机变量应是范围内像素构成的离散型随机变量,对随机变量成立单边 Chevbyshev 不等式如下(证明见附录)
$$ P(x \ge t) \le \frac{\sigma^2}{\sigma^2+(t-\mu)^2}, \forall t > \mu $$
一个会让上式的不等号取等的情况是查询范围内的深度值都一样,而实际情况中深度值常常相差不大,使用上界值估计实际情况不会有很大误差,此处取该上界的值作为 $P(x \ge t)$ 的估计。要计算这个上界,需要得到查询范围内深度的平均值 $\mu$ 和方差 $\sigma^2$,平均值可以通过 Mipmap 或 SAT 等方式得到,而方差可以通过关系 $\sigma^2 = E(x^2) – \mu^2$ 得到,因此只需要另外计算一张深度平方的深度图和它的 Mipmap/SAT 即可。
上面的理论推导得到了重要的结论,即仅需要保存深度图、深度平方图和它们的 Mipmap/SAT,就可以通过单边 Chevbyshev 不等式的上界估计平均遮挡物深度,避免了 PCSS 中遮挡物搜索的采样操作。而 PCSS 中 PCF 滤波的采样操作,则可以通过对估计出的滤波范围大小再次进行非遮挡物占比(即 $P(x \ge t)$)的估计,将其作为可见性的值,同样也可以实现无采样的滤波效果。故 VSSM 的整体流程为
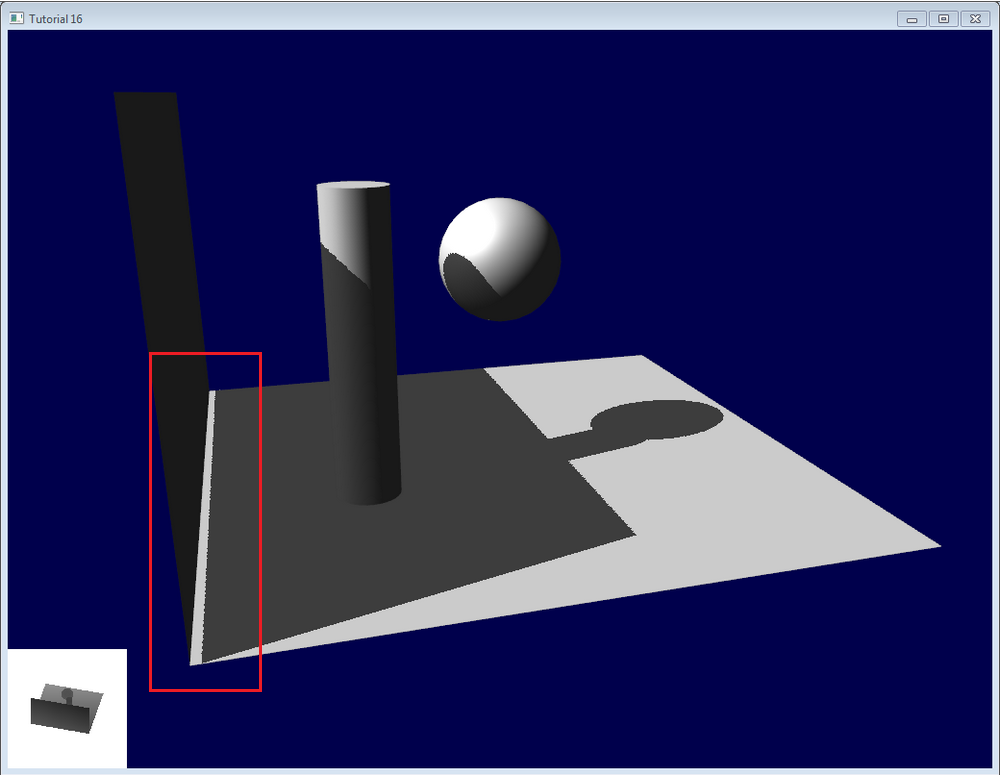
VSSM 利用了单边 Chevbyshev 不等式作为平均遮挡物深度 $z_\text{occ}$ 的估计,然而不等式需要满足单边条件 $t > \mu = z_\text{Avg}$,通常在着色点附近是平面时这个条件能够被满足。当着色点附近的点和着色点不在一个平面上,尤其是远离光源方向时,实际的 $z_\text{Avg}$ 可能比着色点深度 $t$ 更大,此时使用原来的估计会使 $P(x \ge t)$ 的值小,从而使 $z_\text{occ}$ 的估计可能大于 $t$,一些本应在阴影中的像素被判断成不在阴影中,如下图所示。
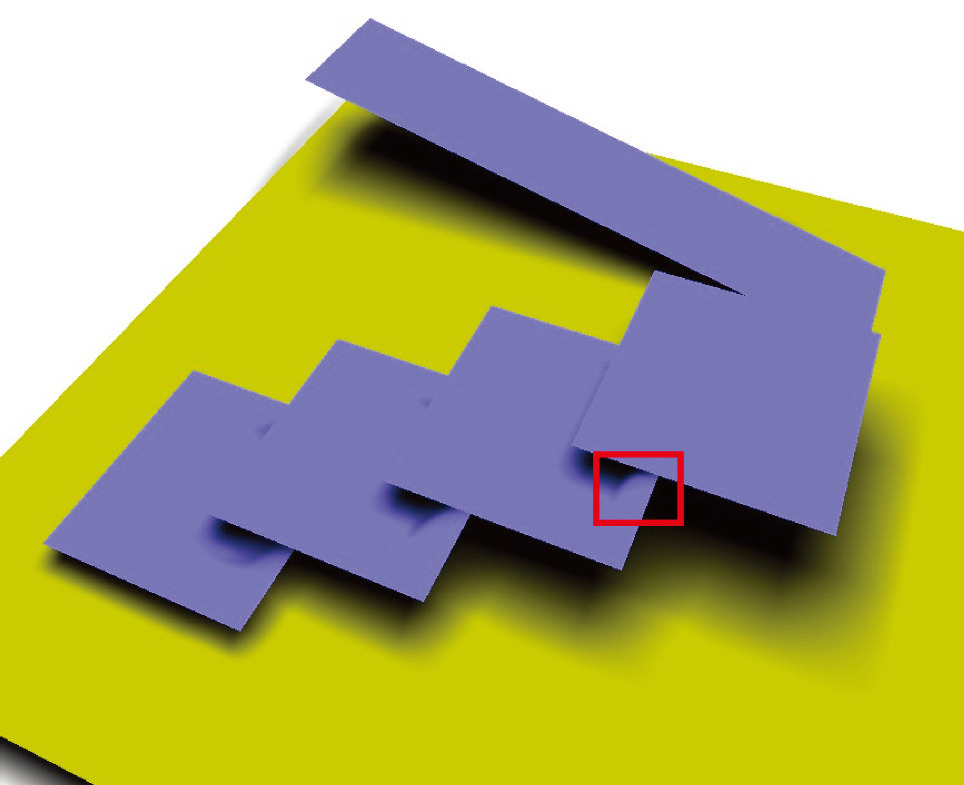
引起问题的原因是着色点附近不是平面,如果把查询范围划分成更小的格子,小格子中的几何会更接近平面,更可能满足不等式的条件。对于划分后仍然不满足条件的小格子,可以简单认为不被遮挡,或使用常规采样方法进行 PCF。
划分后,每个满足不等式条件格子 $w_{cj}$ 的 $E(x)$ 和 $E(x^2)$ 可以通过 SAT/Mipmap 直接查出,记格子的大小为 $T_{cj}$,则可以通过每个格子的信息合并得整体的 $\mu, \sigma^2$,如下所示
$$ \begin{aligned} \mu &= \dfrac{\sum_j E(x)_{cj} T_{cj}}{\sum_j T_{cj}}, \\ \sigma^2 &= \dfrac{\sum_j E(x^2)_{cj} T_{cj}}{\sum_j T_{cj}} – \mu^2 \end{aligned} $$
满足条件格子的平均遮挡物深度 $d_1$ 可以通过 $\mu, \sigma^2$ 和不等式估计得到。而不满足条件的格子则使用上文提到的采样方法,得到其平均遮挡物深度 $d_2$。根据两类格子占比对 $d_1, d_2$ 加权得到最终的平均遮挡物深度 $d$,这样一来就解决了非平面的问题。
此外,方差 $\sigma^2$ 具有的统计意义可以反映随机变量分布的集中特性,如果方差很小且 $z_\text{Avg}$ 大于着色点深度 $t$,说明着色点附近基本都是更深的点,此时可以直接认为着色点未被遮挡以减少计算。
参考资料:https://zhuanlan.zhihu.com/p/111329527
设 $X$ 是取非负值的随机变量,则对于任何常数 $a>0$,有
$$ P(X \ge a) \le \frac{E(X)}{a} $$
证明 对于 $a>0$ 令随机变量 $I = \begin{cases} 1, & X \le a \\ 0, & X < a \end{cases}$,由于 $X>0$ 有 $I \le \dfrac{X}{a}$,两边求期望得 $E(I) = P(X \ge a) \le \dfrac{E(X)}{a}$。
设 $X$ 具有 0 均值和有限方差 $\sigma^2$,则对任意 $a>0$ 有
$$ P(X \ge a) \le \frac{\sigma^2}{\sigma^2+a^2} $$
证明 引入常数 $b>0$,则有 $X \ge a \Rightarrow X+b \ge a+b \Rightarrow (X+b)^2 \ge (a+b)^2$,因此有
$$ P(X \ge a) = P(X+b \ge a+b) \le P[(X+b)^2 \ge (a+b)^2] $$
由 Markov 不等式可进一步推得
$$ P(X \ge a) \ge P[(X+b)^2 \ge (a+b)^2] \le \frac{E[(X+b)^2]}{(a+b)^2} = \frac{\sigma^2+b^2}{(a+b)^2} $$
既然上式对任意常数 $b>0$ 都成立,取右式关于 $b$ 的极小值时 $b = \dfrac{\sigma^2}{a}$,得到
$$ P(X \ge a) \le \frac{\sigma^2}{\sigma^2+a^2} $$
推论 设 $X$ 均值为 $\mu$,则上述结论式可变为对任意 $a>\mu$ 有
$$ P(X \ge a) \le \frac{\sigma^2}{\sigma^2+(a-\mu)^2} $$
取等条件 其中一个充分条件为 $P(X=0)=1$。

这是一位朋友巧合存档下的内容,其中的排版、图片等丢失了不少,我只打算从存档的博文中恢复这一篇最有价值的,其余存档还请移步存档汇总查阅。
按照惯例,在落笔写下这篇文章的第一句话前,是要回头看看去年的年终总结的。2020 的年终总结如此写到:
另外就是,看了一遍去年的总结。怎么说呢,在往回看自己的时候,总会觉得以前的自己 too young,很多时候确实存在偏执和激进的成分,包括这篇总结内提到的许多观点。我一直不希望向别人输出自己的观念,因此各位在阅读的时候也就图一乐就好,千万别当真。
2020, FUCKOFF
今年再来看这些想法和事情,觉得也并不是那么不成熟了。这是否说明个人的观念已经在收敛了,或者已经成长到自己认为成熟的一个阶段了呢?我不知道,但这样的观察会一直继续下去。
2021 年是疫情后的一年,大家都渐渐熟悉了后疫情时代的相处方式,习惯了戴着口罩勒疼耳根,也会下意识扫商店门口的二维码登记信息。唯独我,虽然还是跟着照做,但始终还是不习惯这样的生活,更不喜欢这个后疫情时代;如果有可能,我现在 100% 同意能让新冠疫情从没有在这个世界上发生过;当然这不可能,所以我现在希望能立即将新冠从这个世界上移除。总之,我现在变成了一个,有点怀念过去大家不用戴着口罩逛 gai,也不用带着立场和偏见互相攻击的过去,这样的「精神旧时代人」。
时代在走下行,但看起来我的人生还在上行中。2021 年内发生的种种波折:反反复复的零星疫情、并不能迅速恢复的经济状况、市场和政策的松松紧紧,一切都不容易看清楚,也曾动摇过我对未来状况的预期。另一方面,从结果上看,在这样的时代背景下,我依然做到了许多事情,也见证了很多积极和乐观的现状和预期。我依然愿意在这不太晴朗的现状中期待明天的好天气,以及期望着更接近理想中的未来。
在阅读往年的年终总结时,觉得还是过于意识流 + 记录思考了一些。流水账虽然不太有意思,但作为不同的体验,还是有记下来的价值的,不然就和「人生的意义在于体验」的想法相违背了。因此,本文将分为以时间顺序回顾的「大事记」、记录思考与观点的「意识流」、记录娱乐和感受的「阿宅记」。 ( 起名真难呀,在这三个标题上卡了一小会)
谨以此文献给这个世界。
2021 年的开头,有两次亲近自然的体验。
一次发生在寒假结束回学校前,和母上一起爬山。倒是没有发生什么特别的事,但在快一年没怎么着家的状态下看到当时留下的照片,会突然产生一点想家的念头。在武汉上学的这段时间其实一点都不想家,因为首先宿舍是足够舒适的地方,生活本身也没有遇到很大的困难,另外家离的也不远,愿意的话买张车票 2 小时高铁就回了。大概实在是太久没有回家,最近也挺累的,再微小的情绪也会积累到能够产生情感波动的程度吧。
2021/2/21 摄于十堰四方山
另一次是在武大看樱花,趁着樱花还没全盛人不多的时候溜进了校园,赶了这趟早班车。这是在我高中时就有所耳闻,且心心念念一定要亲眼看一次的景观,由于时间不合适以及疫情原因拖到了 2021 年才真正看到了。武大和樱花是真的漂亮,奈何笔者没什么文采,就不弄巧成拙瞎描写了。
2021/3/4 摄于武汉大学2021/3/4 摄于武汉大学
对我来说没有太大的意义,但很奇葩的一段故事。
被以前认识的一个 20 级学妹莫名其妙暗恋了,还表白了。多亏有消息灵通的友人告诉了我一些事情,让我得以在事情进展前摸清对方的动向,心里多少有点底。本来想着当个老好人演演戏,平静地拒掉,再随意聊点别的就能让事情结束。没想到对方不是很愿意,而且还闹上了,遂使用不予理睬对应,卓有成效。
总之就是非常奇葩,而且我怀疑我不知道怎么和妹子相处,现在对这件事也是一头雾水。
希望她那天半夜闹别把自己整感冒了。
春季学期的上半部分和 wls 及 dtm 组了个队打华为的软挑,还请下了长假脱产打比赛。想着好像有段时间没有这么拼一把了,觉得很有趣,就应了邀。
比赛本身没什么太大意思,觉得比赛题目有问题,哪有换数据集测的,自己对着样例鼓捣过拟合是必然的吧!但是打比赛的这个过程还挺有意义的,第一次不是单打独斗地脱产打比赛,还是与非常牛逼的两位队友组队,时刻都在想着我该怎么不拖大家的后腿。
借着比赛的契机,和 wls 及 dtm 相处了一段时间,他们都是很友善、好相处的前辈,平时的交流时没有感受到任何障碍,分锅干脆利落,讨论时(虽然不怎么能提供思路)氛围也很不错,也有幸以码力提供了重构框架以及实现工具的贡献。在比赛外的时间也会一起吃吃饭,聊聊天,总的来说相处的很开心。
大佬可以是很好相处的,也可以是共事起来大家都很平等坦诚的;心里那一份对大佬的仰慕容易引起一些不必要的紧张,相处了一段时间之后自然也会放下一点。
2021/4/11 摄于华为武汉研究所
因家事回了趟广东,办完之后就顺路在广州玩了两三天。住在北京路南边的天字码头附近,距离商圈特别近,于是就在周围的商业区和景区玩了下。本还想逛黄埔军校的,到地方发现要预约,但错过了最晚预约时间,于是在遗憾中作罢。
广州真是个好地方,好吃的又多,价格也便宜。有机会还想去。
2021/5/19 摄于广州南越王宫博物馆潮汕牛肉火锅 2021/5/19 摄于广州某八合里广东版 nginx 2021/5/20 摄于广州某工地
这趟回来之后发现自己对沙示汽水还挺有好感的,遂网购喝了个爽。
广州之旅约二十几天后,由于广州新冠疫情,在临近考试周被要求隔离,心态爆炸。
隔离点的环境不能算好,饭菜虽然味道还行但很贵。在隔离点自然很难复习进去考试,于是直接进行了一个烂的摆,每天最大的乐趣是用花露水杀蚊子,前前后后能弄死了几十只。
2021/6/17 摄于华中科技大学隔离点
趁着出差讲课的机会在南京玩了一天,吃到了盐水鸭之类的,去总统府逛了一圈。
2021/7/4 摄于南京总统府
在 4 月拿下了天美的实习 offer,7 月要去深圳打工。打工之前要搬宿舍,以及初到深圳的一些新鲜见闻。
拿下 offer 的过程还是比较曲折的。在朋友的煽动下随便写了点简历,找了好几位前辈征求意见,然后小心翼翼地投出去。先后参加了腾讯、网易雷火的游戏客户端实习生、米哈游的游戏服务器实习生招聘,笔试倒是过得比较顺利,主要是面试普遍被一面问到。腾讯更是撑到三面后被大人物问到觉得自己啥都不会,但居然被放进了 HR 面,聊聊天后也就顺利拿到 offer 了。
搬宿舍是这个过程中做的最糟糕的事情,因为一个错误的预期:一天内搬完整个宿舍是可能的,因此在时间计划上没有留出任何余地。那天起得很晚,中午吃完饭后去新宿舍办手续,随后发现房间卫生状况糟糕,于是开始打扫。打扫结束就临近傍晚了,于是速度开始搬运东西,凭着小电瓶车和从顺丰买来的无敌可靠大纸箱一趟趟地搬,从傍晚忙到了深夜 2 点,连宿管大叔都有点可怜我。
带着睡眠不足上了高铁,一路到了深圳。初到的观感其实特别新鲜,因为城市设计比较新潮。随后便是入住公司的中转酒店,四处玩玩,租下来房子,入职学习干活,后面就是另一个故事了。至少在入职之前,玩的这一段时间还是蛮开心的。
2021/7/7 摄于深圳北站
毕竟是第一次的打工,还是在腾讯这样的大厂,很难说没有抱着一些幻想或者期待去投入。就像其他的活动那样,刚开始的时候因为有幻想和新鲜感在,不会有太差的体验;反而是久而久之,新鲜感褪去,一些不尽人意的地方的折磨也积累了起来,渐渐地就开始难受;在腾讯的实习便是如此的一段经历。
入职礼包 2021/7/9 摄于酒店
base 在科兴科学园,初见逼格十足,楼上都是玻璃幕墙,而楼下小吃、餐馆众多,看起来生活质量会很高。但是接触之后才知道科兴的办公环境比滨海还是差了一些,而且餐馆的消费普遍很高,我一开始还不是很能接受那样的消费水平(当然后来都习惯了)。
在腾讯的部门和人都很不错,mentor 和 leader 都是业界的前辈,很好相处。
虽然是实习,也并没有从很 common 的学习阶段开始,而是直接从具体的需求开始试着做。我接到的需求大多是不紧急、但很有研究价值的探索性课题,一方面能够从这些课题接触到对应方向的基础要件,也是一种很好的学习;而没有 ddl 就不至于被做不出来的压力压垮,可以慢慢入手;最后,如果这些课题的探索能够成功,无论是落地项目带来的成就感,或作为一段经历写入简历,都是很有重量的收获。除去自己太菜、做不出东西的痛苦之外,我还是很喜欢这样风格的培养方式。
在这个过程中,mentor 和 leader 也给了很多的指导,也会经常在一起交流感想。记得在中段的时候 mentor 问了我一次对什么方向感兴趣,说如果想接触其他的方向,也可以让对应的同事安排。当时的想法其实是想接触一下实际的 gameplay,不过后来还是选择了一个更大的课题继续做下去。大家对新人真的很友好。
腾讯科兴 base 2021/7/24 摄于科兴科学园
说完了要吹的部分,就该说说不吹的部分了,不过这里大部分因素其实在自己身上。
房子租在南油,因为是不同公司的同学合租,我是 base 离房子最远的那个,每天早上要 8 点起床赶班车,下班也要坐 9 点的班车回家。工作时间倒是不算长,但是把通勤算上,每天相当于有 13 个小时在外面,所以其实相对比较累。
暑假其实实习不是唯一要做的事,当时天真的以为自己能顾得过来,三开了冰岩的活和 GAMES101。最开始的时候,是晚上吃完晚饭后分一点时间出来做这些事情,以及下班回家之后做一会,但这些时间效率都不高,导致了晚睡。叠加上前面提到的通勤问题,其实后期长期在睡眠不足的状态下。
另外一个压力来源就是做不出来。实习后期的一个活做了一个 demo 来测试,demo 本身倒是写的很顺利,但测试出来的结果怪怪的,自己也分析不懂,于是就在反反复复的调整和尝试中耗费了大量时间。因为特别想亲手把这个结果落地到项目里,在离职前留下点自己的痕迹,做不出来的时候其实是比较着急的。
此外,一个中学时结识的朋友,仰慕的人,也是游戏开发的引路人,不幸发生了意外。这件事情其实是更早时知道的,但当时不知道应该怎么处理,于是拖到了暑假才和其他的友人一起开始处理。每每想起这件事都会有很多思绪泛起,更在当时推动了勉强自己的想法。
8 月份的时候,冰岩的 ddl 几乎没有一个赶上了,而因为睡眠不足又导致了感冒之类的毛病,最严重的一次整个人生理上地难受。
整个人处于一种,没什么大病,但是头疼、没精神、吃不下饭、躺着也睡不着的状态,以及肩关节依然酸着
8/25 的说说
后来和 zcy 聊了许多,把沉浸在痛苦里的自己拉了出来。虽然很不甘心承认我没办法兼顾那么多事情,但是生活总是要过下去的,效率也总是要提高的。为了现在觉得更重要的事,放下一些可能是更好的选择。
展开的话放在后面吧。
实习的期间其实也没少出去玩,这里列举一下在深圳去过的地方。
2021/7/10 摄于南方科技大学
刚到深圳时去友人的学校窜门,南科是真滴有钱,楼都修的巨漂亮,宿舍条件也很好(除了一些很迷惑的设计)。友人在宿舍楼下的公共面积里搞了个学生酒吧&咖啡吧,简单喝了点东西。
2021/7/17 摄于腾讯滨海大厦2021/7/17 摄于腾讯滨海大厦
这是部门团建去了滨海的运动区域体验攀岩。滨海的环境真的好牛逼啊,连攀岩设施都有。暑假的时候身体虽然废柴,不过撑一撑最后还是爬上去了,好耶。
2021/8/1 摄于深圳湾公园
深圳的城市规划真的很不错。工业区和生活区基本上是交错排列的,通勤不会太长,绿地公园的开发也比较多。8/1 这一天来深圳湾公园夜里散散心,大概走了一半的步道。如果在白天,这里看看海还是很惬意的,晚上的话稍微无聊一些,但大热天吹吹海风也挺舒畅。
2021/9/4 摄于莲花山公园2021/9/5 摄于梧桐山景区
临走之前在深圳各个地方逛一逛。其中爬梧桐山的时候,因为身体状况实在是太差了,上一小段台阶心率就会飙到 140,只能走走停停地追着 csy,还是挺丢人的。那时下定决心说回学校以后一定要把日常锻炼提上日程,倒是坚持了那么一小段时间,后来又鸽了。 人 类的本质!
要说今年买的最值的几样东西是什么,一定是刚开学的这几样:
刚回学校的时候趁着手里有点钱,入了 16GB 内存和 AX210 网卡给电脑升到顶配。后来机械硬盘寄了,于是申请了点援助经费把 SATA 位换了一块 1TB SSD。吃了同学的安利买了西昊 M18,自坐上之后腰再也没疼过。
这些东西都是实打实提升生活幸福感的内容,电脑的性能提升了以后开几个 JetBrains 的 IDE 不会再担心性能问题,而从高中困扰到现在的腰痛终于被解决,也是真的很爽。
话越短,事越大。
9 月拿到了米忽悠的实习 offer。
米忽悠的校招礼盒 2022/1/8 摄于宿舍
经过暑假的影响后,我把冰岩的锅推掉了,在程序组招新结束之后就转到了游戏组。其实之前差不多也都互相认识过,转过来以后也相处的很愉快。但是自己的经历还是有点不对,没有办法直接转化成即插即用的生产力,这一点上面还是感到有点不安的。
游戏组联合主办的纸上游戏工坊活动 2021/10/30 摄于启明学院
12 月的时候去了一趟深圳参加 CCSP,有幸打了块金,但由于路程匆忙没留下什么照片记录。
这块金其实挺意料之外的,因为算下来已经是退役的第 4 年了,很难说自己还剩下什么经验或者直觉去解决算法题。也因此把 T1 签上到之后,T2 只打了个暴力,后面也没再怎么碰这道题。
优势更多是在偏实现的 T3~T5 创造的,尤其是 T5 给了我巨大的帮助。T3 由于确实不怎么能看懂,看懂也不怎么想的出来怎么实现看起来很麻烦的量子操作,尽最大努力打了看懂了的部分,但是好像被卡了常数。T4 开的比较早,打了个 LRU 上去签上到,很快就被卷下去了,不过由于中段主要在看 T5 暂时放了放,最后卷回来的时候是在调 LRU-K 的参数 K。T5 本身还是比较有想法的,因为之前简单看了下 Redis 的可持久化原理,按部就班地先用 unordered_map 把基础要求打出来,然后用文件 IO 持久化指令,再加入分段快照,没怎么调试就写完了,实现了一血 + 常驻榜首。后来思考了一下为啥能榜首,可能是因为实现比较 C 风格,文件也基本上用二进制 IO,可以省掉流/格式化 IO 的一些常数。但也有点问题,比如 buffer 之间的复制次数还可以继续优化,以及合理使用 reinteprete_cast。
被邀请去给高一的 OIer 讲组合数学,因此寒假离校后借住 qsf 家里以便线下讲课 顺 便撸猫。
qsf 家里的布偶 2022/1/21 摄于 qsf 家里
讲课倒是很通常的事,不寻常的是,在备课的过程中找回了一些学 OI 时没能发现的乐趣。
学 OI 时因为着急点技能树,只记结论而不深究原理,后期靠题海战术强行点熟练度,导致整个学习的过程其实挺无聊的,也有很多原理是在退役后想明白的。
在备课的时候,因为之前试讲发现学生的水平能够接受原理性的知识,于是萌生了扩展范围的想法,自己也开始看离散教材和《具体数学》来挑选适合放进去的内容。在这个过程中重新学了一遍生成函数,并且手推了挺多的式子,感觉这种把单个的函数与无穷数列联系起来的处理方式非常精妙,而且和信号里时域-频域的关系还有点像。
学无止境,虽然好像现在学这些也没太大作用,只是希望能给学生带来一些不一样的东西,顺便如果能安利他们以后走上数学或者 TCS 的道路也挺好的。
摘自南京大学《操作系统:设计与实现》课程
这里主要记录今年的一些看法,类似去年的年终总结的风格。
开头也提到了,今年再来回头看去年的年终总结,那种 too young 的感觉有所减少,也说明自己的思想在往收敛的方向发展,不知道这是否是一件好事。
内卷是什么呢?2021 年,我又把这个问题拿出来思考了一遍。
狭义的内卷,一般指的是需求太大而资源太少,导致竞争升级的现象。而由于资源的供给不由参与竞争的这些人提供,而是由上层建筑来决定,所谓的这个上层建筑又由于发展阶段的原因并不能真正满足每个人的资源需求。
如果这样来解释内卷,其实作为内卷参与者的我们是无力去改变现状的,因为它的原因是深刻而复杂的,是短时间内不能很好解决的难题。而且内卷带来的结果也不一定是负面的,因为竞争本身也是一种筛选的过程,卷赢的人或许在统计学上更适合得到这份资源。
那么为什么我们要反对内卷呢?
因 为作为内卷的参与者,我们被升级的竞争折磨得死去活来,竞争的压力实在太大,它压垮了我们的自信,压坏了我们的情绪。我们在参与竞争的时候总是希望自己是无情的学习机器,能够以 7×24h 的可用性全功率地参与竞争,因为这样才能卷赢。但在实际做这件事情的时候,感性会告诉自己这是坏的,人有社会化的需求,有与他们社交、共情的需求,看着自己一步步向讨厌的方向堕落,迟早会开始崩溃。
因 为内卷的局面不总是公平的,就算是公平的,也会存在囚徒困境和边界效应这些讨厌的情形。参与竞争的我们最相信的事情是:只要付出努力,那么无差别的努力就可以转化成取得的成果。公平性是这一命题成立的关键,如果有人破坏了公平性,相当于所有人付出的努力被否定。其次,不合理的规则会导致囚徒困境,竞争时的我们都可以当做理性的博弈者,如果规则中存在囚徒困境,所有人会让彼此陷入互相伤害的局面,而事后又会开始憧憬所有人在互相受益的局面的可能性。再次,边界效应是升级的竞争中很容易遇到的问题,付出的努力无比巨大,但在最后的一段时间里却没能获得显著成果,尽管努力转化成果是存在的,但容易使努力的积极性受损。
也许前面的两个原因是共性的,这一条可能有我自己的个性。 因 为内卷让我被迫面对那些讨厌的事情,让我在短期内离追梦更远。例如我的专业和发展方向是有偏差的,但为了提升学历,我必须投入较大的精力到专业课程里,而其中有一些课程是我不太学的明白的,支撑我学习的动力会随着时间推移减弱。虽然嘴上说着热爱学习未知,也很想对每一份未知都保持着好奇心,焦虑多少搞的自己还是有点过度在乎那些功利的考量。
这些是自己在面对内卷遇到的困难。而如何解决这些困难呢?这可以从这一年的经历中提取出一些想法,但并不能完全地解决这些困扰,毕竟,现在的我仍然面对着其中的一些困扰。
找 一个信得过的朋友,坦诚布公地聊聊天。这是在我身上最有用的一种方法。和你的朋友完整地描述你现在遇到的困境,你被卡在了什么地方,你有哪些选择,你的想法是什么。和他辩论为什么自己做不出决定,别的选择有什么好处,让他说服你选择你下不了决心的某一项。反正在我这里,我一般都能被说服,并且大胆地尝试改变。
娱 乐。这是一种我经常用,但是效果不好,却又不能没有的方法。娱乐一定是生活中不可或缺的要件,生活总有不如意的地方,长期以来就会积累出所谓的磨损,而娱乐可以在有限地减少一些磨损。具体来说的话,我喜欢吃甜食、吃大餐、去 KTV、去自然风光好的地方游览、看番和打游戏。不过这个有一个挺大的缺点,大部分项目还是有点费钱。
转 移注意力。由于我长期处于多开模式,这种方法也很常用。分一点时间出来,做一些更有意思但当下不是那么着急的事情,比如复习备考之余去写点代码,学点图形之类的。
好像扯得有点远了,这个部分的主题是「内卷的未来」,也就是想要探讨这个内卷的时代的未来会发生什么。那么开门见山,我认为 未 来不会发生什么。
内卷其实只是起源于类似 meme 的表达,大家觉得这样来描述竞争很有趣,就这样传开了。内卷背后的那些事情,资源的不足、压力的上升、焦虑的气氛、不良的环境,这些都早已存在,只是在这个时代里我们用内卷称呼他们,并且这个时代的环境稍微更加恶化了一些而已。
既然如此,平常心看待这个现象便可。以前的前辈们如何面对竞争,如何探索自己的人生,我们依然可以效仿着在自己身上实践。
很多 ddl 没赶上的时候,我都会因为这个问题而自责。定下了一个比较激进的 timeline 以后,下决心说要逼自己一把,或是有许多机会舍不得放弃,而决定多开来兼顾两方。这样的计划就要求自己在一定的时间内创造比悠闲时更多的成果,也就是说要提高效率。而大部分情况下,这种尝试都会以失败而告终。
这里列举若干个年内发生了的事情。例如实习时希望多开冰岩的项目框架与 GAMES101,分配了晚上和下班后的时间,但实际上效率低下,只顾得上实习本身的事情了。而后来联系到浙大的老师之后希望在大三上多开必修课和 MIT 6.837,最后也以牺牲 6.837 的产出而告终。
存在提高效率的方法吗?一个人的效率是否有上限,又是否与悠闲时的效率等同?
一如那些讨论成功学的书的结论,提高效率的方法是当然存在的。比如可以通过日计划、周计划来精确地分配自己的时间,比如将需要完成的事情列成清单并标注 ddl,以便随时查阅来安排短期规划。这些方法都有过尝试,但最后也都放弃了,最后,研究这些方法反而显得很没有意义。
我自认为我是一个可以为了有趣而加班加点肝的人,而对于那些不感兴趣的事情,则会一拖再拖。而在这个拖延的过程中,用来打发时间的办法却又是一些水群、睡觉、出去玩一类的短平快娱乐活动,在娱乐中对时间流逝的感知不强,从而忘记了自己原先的规划。
一个在自己身上实践成功了的方法是: 立 即去做。有意识地在 todo list 里挑选一个事情,马上去做,试着专注在这件事情上。如果能够实现这种专注,那么专注带来的惯性和事情有进展的反馈会推动自己一直做到结束,甚至进入一种心流状态。
然而很多时候,问题也并不出于自己的拖延上,而是看起来时间很多,却有大量时间被打碎,不足以形成专注或干不完就会被中断。如何利用碎片时间也是一个我暂时没有找到答案的问题,目前而言,我对手机上的信息流已经感到厌倦(除了水群),且正在尝试随身带一本不烧脑子的书阅读,看起来还是比较有效果的。
在这一年内,我的消费观念也发生了些许变化。首先是被深圳的消费水平彻底打碎了原有的价格认知,并且在拿到实习工资时甚至觉得自己又消费得起了,不知不觉变得更愿意消费了一些。在这之外,我也建立起一种认识, 如 果能用接受范围内的钱来换取方便或者节省时间,一定是赚的买卖,该打车的时候打车,该购买服务就购买服务。至少这样的消费能切实感受到生活变得容易了一些,一些琐事从 todo list 里需要分出精力应对的项目变成了一笔交易,在有钱的时候真的很爽。
在游戏或影视中很容易建立的心流,放在其他的事务上变得困难无比。尽管如此,人为地引导心流的尝试也有少数几次成功,希望在来年能够掌握这种方法,毕竟还有很多想做的事情需要「逼一逼自己」。
2021 年里,我做出了一个仅次于人生走向选择的决定: 放 弃一些虽然想做下去,但长远来看对发展无益,精力上也顾不过来的事务。这条原则源于 8 月在深圳过的很难过的那段时间,在冰岩的后端 ddl 始终没法达到,而且也分不出精力为招新准备材料。和 zcy 夜聊交流了很多想法以后,觉得已经到不得不把手上的事情交出去的地步了,于是就去和当时的主管谈心,把项目和组长都交了出去,剩下的只有一个招新的事情。幸运的是,在事情结束的后来,我得以转入游戏组,也和游戏组的大家相处得很愉快,这样的结局比切断一切联系要稍好一点。
另一方面,2021 年我这样一句话有了更深的感触:
一个人的命运啊,当然要靠自我奋斗,但是也要考虑到历史的进程。
引自某人语录
2021 年,反垄断、市场监管、文化准入等等铁拳向互联网行业砸下,与之同时,版号、未成年人限制、媒体的又一次污名化也影响了游戏行业。
记得是在一次上班等电梯的时候看到的有关游戏行业的信息,当时就在想,从禁令解除这么长时间以来,游戏行业发展到今天这一步已经很不容易了,这样做到底是图个什么呢。我自己当然想不出什么答案,但多少有些担忧自己的未来,2 年后毕业的自己会不会刚好踩进行业低谷的坑中。
在 2020 年定下未来的路线以后,我一直抱着一种「现在先把自己的技能树点满,到真正参与工作的时候,只要足够强就能站着把钱挣了」的心态来预想未来,也因此一直保持着对未来乐观的心态。然而,看到大环境的这种波动时,很难说不会开始一些担忧,而担忧又伴随着「就算变成无敌强人,局势也不是我能扭转的」这样的无力感,或许存在不小的可能性,未来真的站起来也没法把钱挣了。
再来谈谈今年发生态度转变的契机吧。实习的后段其实整个人都非常低沉,原因有很多,例如手里的工作进展不佳,例如计划中的多开最后都没顾上,更重要的是这样一个消息:一个仰慕已久的前辈遭遇了意外。意外的到来都是很难接受的,因为它没有什么理由,也没有什么预兆,任何一个人都很难接受一个人突然从你的面前消失。
今天要讲一个故事,一个关于少年和一位 mad scientist 的故事。 少年还是孩子的时候,认识了一个比他大 5 岁的中学生。是因为打电动而认识的,他们都是宅,而且也都爱打电动,所以熟悉的很快。 中学生是一位科幻爱好者,很喜欢 Half-Life,他在另一款游戏里重现出了 HL。虽然少年没有玩过 HL,但是这个重现版本也让他觉得中学生很厉害。 中学生发起了一个社团,作为主催经营着社团的活动,上面的这个重现也是社团的作品之一。少年在这个社团里,还有一些朋友在这个社团里。大家都很喜欢打电动。
有一天,一个新的点子在社团里激起了水花,在游戏里复刻科幻动漫难道不是一件很炫酷的事情吗?少年和中学生都喜欢看这部动漫,抱着很大的兴趣,和朋友们一起启动了这个项目。 少年一直觉得中学生很厉害,也想学着在游戏里做一些炫酷的事情,因此他去学习了 Java。这次,是他第一次能在作品里帮上忙—-> 虽然是一些无关紧要的小东西。他尝试看过那些中学生写的代码,但是一知半解,没有深究下去。 中学生变成了大学生,他的实力只会更强。看到作品一天天趋于完善,甚至有着出色的效果和质量,少年真的很佩服他! 他曾经说过,他想看到完全潜行技术变成现实,想制作出这样的游戏。所以,复刻已经无法满足他了,制作独立游戏是他的下一个目标,于是他又开始了新的征途。 这个时候的少年在做什么呢?少年是中学生,而中学生必须要通掉高考的副本才能变成大学生。少年
在苦苦地打本升级,虽然他也尝试过有些不同的道路,但少年做不到他那样与众不同。少年想,等我成为大学生以后,我也想变成能做出炫酷东西的人。少年和他不再有以前那么紧密的联系了,只是默默地刷等级,默默地仰慕他和他的作品。
少年终于变成了大学生,和他是同一个学校,可是早在进入大学之前,仰慕的那个人已经毕了业,进入了一家最接近他愿望的公司。少年也想进入这家公司,或许是因为出品的游戏好玩,或许是因为少年一直在追寻他的身影。
少年的专业不是计算机,也和游戏开发不沾边。少年加入了他曾经在的团队,也不是做游戏开发想换的事情。少年觉得这样也没什么不好,便顺其自然地生活了下去,少年知道他仍然在继续他的征途,但是已经完全不知道他在哪里,他的征途又长什么样了。少年只是觉得现状很舒服。
心里的一丝念头让少年走进了一些他本不应进入的课堂,比如《计算机图形学》,又或《游戏学导论》,少年发现,虽然自己的专业也很好玩,但这些课程让他沉迷其中,少年觉得自己丢掉了初心,应该做点什么弥补一下。少年也许回到了若干年前的心态,但现在,他终于明白了那位日日夜夜奋战于兴趣作品的前辈,是什么样的东西给他做得更好的力量。这真的很有意思。
少年迈出了第一步,那是一门网课,他看了一半,作业也做了一半,却因为不知道什么原因断掉了。少年的第二步是学习基础知识,但这一步甚至从来都没能迈出去。至于阴差阳错跨出了一大步的第三步,少年得到了一份offer,岗位和他的偶像相同,只是不是一家公司。当然,少年显然会尝试他的那家,因为资历和经验实在太白,少年显然四处碰壁。
少年在定下目标后,变得更忙了。是因为需要完成目标?不,是因为课更难了,事更多了,团队也有需要出力的地方。少年在他的目标上没有成果,但是他已经被各种事情耗尽了电池,却又缺乏加快充电的方法。少年觉得自己很废,觉得自己做不到偶像那样的万能而强大。
少年撑到了入职的那天,他觉得这是自己离偶像最近的时候。但是,少年实在对这个业界了解不多,他从事的工作和偶像并不一样。这不是因为少年选错了职位,而是因为这个工作真的有很多方向,这是少年第一次对这个业界形成了最真实的认识。在若干天学习、工作后,少年觉得自己成长了许多。”也许这样,以后我真的能获得与他共事的机会,也能帮得上他的忙了。”少年在辛苦但收获颇丰的工作生活中偶尔勉励自己。
但是少年有了一件不愿意相信的事情。不知何时不知何地,也不知为什么,偶像永远地离开了这个世界。这个消息实在是过于震惊,也没有能确认的渠道来证实,少年始终不愿意相信。接到offer的时候,少年第一时间告诉了他,这是在两个月前。为什么才过去了这么短的时间,事情变化会这么大呢?可望而不可及的那个身影,突然消失了。少年很懵逼。
重拾起那些有他的身影的回忆,少年的成长里到处可见对他的崇拜,少年追随了他很久,尽管迷茫过,最终也回到了他走过的道路上。他是少年的引路人,是影响少年人生的重要之人,是会被少年永远记住的人。 少年心中的那位已经离开了。少年要怎么做?他是一个 mad scientist,曾经有着中二的想法,最终竟真的走向了那个想法。他是对游戏很认真的一个人,为了有趣的点子,他能点出所有需要的技能树。他喜欢思考,他热爱生活,他有文学和艺术的兴趣,他依然喜欢纸片人,甚至还偶尔临摹一些。少年想继续成为像他一样的,能做出很酷的东西的人。 少年觉得自己可能还是太废了。但是少年会尽量努力,尝试变得不那么废。
2021/7/30 的说说
回想起记忆中模糊的片段,其实从事什么样的工作,未来接触什么样的事情,自己早就有过一个答案。只是在刚进入更广大的世界中,因为选项太多而误打误撞走上了别的路线,又带着一份随遇而安的无所谓心态就这么走了下去,也没有过多的考虑。这件事让我回想起了中学时单纯的想法,此时我这样的状态是不是也是一种遗失了初心的表现呢?在这样的不安中,我决定来一次急刹车,把方向强行掰过去。
2021 年中,我总有一种浓度在慢慢流失的感觉,因为看的番越来越少,游戏也很难再有动力打开。仔细回想起来,其实是分了太多的精力在焦虑和内耗之上。每时每刻都在思考 ddl 的优先级顺序,在纠结如何为接下来的一片时间创造意义,并为刚刚浪费的一片时间感到懊悔。
娱乐是生活的必要组成部分,影视、读书、游戏,乃至运动,都可以成为组成娱乐的项目。问题在于,冗杂事务将时间打碎成一片片的零散片段,依赖沉浸体验的娱乐项目很难进行下去,一段时间离开了环境很有可能就回不去那种状态了。因此, 有 必要在未来规划一些专门用于娱乐的大块时间。
早就听说一个高中同学非常喜欢这一部作品,也是古早时代京阿尼的著名作,抱着仰慕的心情看了下去,因为太符合个人兴趣而立即被圈粉。
轻音的日常剧幽默得很自然,经常会笑出声音而不自知,感情戏则细腻而动情,强烈的感情会被掺杂在一些反而并不是很强烈的行动、对话中表现出来。毕业时阿梓喵的一句「请不要毕业」,随后奏响的《相遇天使》,在这样的氛围中很难让人绷得住。
音乐是轻音中给我留下最深影响的元素。很早以前就听过 ED 之一的《Don’t say “lazy”》,当时就树立起了澪帅气的形象。真正看完了整部番之后才体会到其音乐完全没有局限于 ED 这样的风格,OP 类似唯的轻快少女风格,插入曲中也有不同风格的作品,让人很难忍住不跟着唱。本身个人比较喜欢日式流行音乐,受轻音音乐和唯学琴经历的影响,更是有点想去接触一下吉他了。
当然啦,就我这样三分钟热度的学法,肯定不会有什么结果。预想到这一切的我最终还是放弃了这个念头。
相当小众的一个题材,讲述一位对文字词语天生具有兴趣的编辑参与词典编撰工作的故事。剧情平平淡淡,感觉重点更像是把一些常人并不知道,也不会刻意关注的幕后故事放在台前讲述,用于支持这些带有一定社会公益性质的事业发展,同时也能满足观众的猎奇心理。
番剧之外,更多的是让我想起了初中中二时期的一些「文学创作」。当时还会刻意地阅读和模仿一些近现代作家的风格,并且认为文化素养是有必要积累的东西。而今已经完全变成了没有任何文化素养、铁板一块的工科男,笑死。
伊蕾娜是真的可爱!
观看的体验感觉非常新鲜,观感类似于公路片,主人公伊蕾娜是能力很强、能解决各种问题的理想人设,但她并不会主动参与到各种事情中去,而只是旁观着事情发生。因此,作为主人公的伊蕾娜更像是一位讲述者,虽然她有自己的想法,但是并不会像爽文那样,利用自己的能力来改变那些不美好。这种新鲜的观感,加上非常漂亮的人设,以及还算不错的剧情,创造了非常好的观看体验,也从此开始喜欢上了单元剧的格式。
但是全剧结束之后,反而让我自己产生了一种落差感。在观看过程中,我倾向于与伊蕾娜产生共情,在她的视角参与到事情中,理解她的心情,从而体会到了一种「自信爆棚、随心所欲、个性张扬」的感觉。伊蕾娜被刻画成相当理想的形象,出身于学者世家,靠着惊人的天赋成为了魔女,几乎没有遇到什么挫折。而反观自己的经历,每进入一个更大的圈子中,都会感叹于别人的牛逼,而自己的能力有限(最近甚至总感觉已经顶到了这层上限),追赶不及。从代入理想角色切回现实视角的时候,难免会产生如此的落差感,而感受到一种模糊的伤感。
总的来说,还是很棒的观看体验。
自看完《魔女之旅》以后就对单元剧方式叙事的作品有兴趣,进而开始看大河内一楼的一些作品。死后文便是其一,在这一世界观里,死者可以从死后世界向现实世界中的人寄一封信,由邮递员负责将信交给收件人。故事从邮递员文伽的角度展开,她只负责派送信件,而几乎不参与围绕信件的故事。而剧情后半,文伽也被卷入有关死后文的故事,向观众解释了她的背景故事。作品的设定与剧情表现不错,以死后文的设定引起有关道德伦理的思考,题材新颖深刻。
相当不错的一部作品,将爽文发挥到了极致。同样是大河内一楼编剧的一部单元剧作品,更是引入了乱序叙事,体验非常新鲜。
世界观建立在中世纪+未来科技之上,少女们承担着「间谍」的沉重责任,古老且有些脏的环境风格与科技的发达形成对比,同时少女们漂亮的身姿与其职业、格斗技艺也形成对比。实际上,少女们只是政治博弈的工具,但她们对此没有怨言,而公主和间谍之间还发展出了一条暗线,这两条线在故事中相辅相成,朝着积极的结局发展着。
整部作品的各种表现都围绕着爽这一个字来设计,强烈的设定对比,打戏中的激烈对抗表现,看似柔弱的少女总能化解危机,在紧要关头实现漂亮的反击,可以说从头上瘾到尾,非常值得观看!
第一季是有关特别周和无声铃鹿的故事,从观感上来看更像是为了给游戏做广告。而第二季中,我感受到了对东海帝王这一名马的厨力放送。
东海帝王的三次骨折,一次终结了「三冠」,一次打破了「不败」,最后一次夺走了她登上赛场的机会。她有过失落不振,有过摆烂养老,曾放下了所有的追求,彻底躺平。但是最后一次,承载着众人的愿望,她还是走上了赛场,甚至以第一的成绩完赛。大起大落的经历,加上编剧有心的铺垫与氛围营造,给当时的我狠打了一针鸡血。
现在回想起来,有马纪念那一集喜极而泣的心情依然能够震撼人心。Cygames 是神!
补完了 LL、LLSS 剧场版以及虹团和星团的 TV,算是怀旧一下吧。LL 系列作品本身倒是表现普通,但这个符号对应的那个时代,和在那个时代发生的种种故事,却是人生中深刻的回忆。
NOI 失利后,尽管心情很差,还是去参加了当年的文艺汇演,约到了一些不认识的 LL 众在 NOI 现场唱了《愛してるばんざーい!》。已经记不清当年约到的人分别是谁了,只有一位现在还在保持联系,LL 这个符号和 OI 生涯的回忆通过这段经历联系起来了,因此当补到 LL 系列,尤其是初代,总能回忆起当时的情景。
以简单的单键节奏游戏为核心的一款独立游戏。但其质量主要体现在交互设计和演出上,Boss 关中多轨混合以及窗口的画面效果、移动效果体验都很出色。同样地,音乐也很好听!
味道很正很正的粤语文字冒险!好久没有玩过文字冒险之后,体验了一把非恋爱题材+粤配的这个作品,各种方面让人耳目一新。网上看了一些关于世界观和暗线的解释,文案设定老师在这块是下了功夫的,非常推荐。
通过 BGM 先认识到的游戏,本身是典型 JRPG,玩法核心在采集和合成系统上,通过这个解锁更多的道具、工具、药品之类。画面和模型品质一般,BGM 出色,跑图的感觉也不错,解谜属于偏简单的难度。玩这款游戏更多地是因为莱莎可爱以及个人就是比较喜欢 JRPG。
第一次体验高难度动作游戏,在精英怪处死了几十次,和训练怪又练了几十次,看了下攻略视频,才过去的。一直以来游戏战斗喜欢用很保守的策略去放技能之类,但是在只狼这里更看重时机和节奏感,也就是所谓的手感,因此刚开始上手时会很不适应。此外,手柄默认绑定的按键是 LB/RB 这点也不是很适应。
对我来说这类游戏是第一次体验,找手感-训练-实战攻破的过程还是很有趣的,只是可能不是很有时间来反复练习。
其实没有什么好说的,只是想晒一下(手动滑稽)。
这本书中围绕着一些已经发生过的、具体的游戏实例,来向读者展示游戏为我们带来的美好前景,以及游戏可以带给我们的超能力。阅读这本书本身是一件非常上瘾的事情,因为自己也是游戏玩家,相信着游戏能够为我们带来美好的未来,又配合书中的讲述,在脑内构建出了一个相当理想的世界。
可惜的是,这本书的成书较早,而在今天的角度来看待当时提出的这些愿景,只能说终究是错付了。或许比起合作和社交,我们更喜欢攀比与竞争吧,毕竟这是一个内卷的时代。
但是我还是很推荐你阅读这本书!我觉得我对于一些问题的看法,因为阅读了这本书,并接受了其美好的愿景后,变得积极了一些。我愿意为创造这样的美好未来付出一些努力。
一本在策划角度深入理解游戏中的人工智能的书,还在看。一个最深刻的观点是,在游戏中应用人工智能,其目的是利用技术手段给玩家带来一种体验,因此人工智能可以不那么智能,可以是决策树或状态机一类简单的模型。优秀的玩法设计、战斗设计才是体现出这些技术在游戏中的价值的关键点。
不出意外,这一篇年终总结又鸽了好久,最终完成于开学后的 3 月 10 日凌晨。此时的我已经记不起创建这篇文章时的心情了,那时有着许多想表达的内容,以及对过去一年的复杂想法。因此,只能草草收尾,补全一些当时中断未写的内容,趁着记忆还在赶紧留下这些记录。
2021 年真的发生了很多,第一次发现自己的看法在收敛,第一次觉得自己的能力顶到了上限,第一次向行业迈出一步。最重要的是,一个曾经遥不可及的,可能能被称作梦的目标,在这一年终于达成了。现在回忆起这段经历,依然感觉到如梦似幻,有些不太真实。
想用积极的态度为 2021 年结尾。在大三这一年肯定会发生更多能够决定人生走向的事情,我正在为此做好一切能够做到的准备,等待时间为这些事情埋下种子,萌发新芽,最终得到结果。我愿意相信努力能够收获回报,未来能够被我掌握,目标能够通过进步来达成。希望在 2022 年再撰写年终总结时,能等待现在埋下的种子产生结果,骄傲地向世界展示这一切。
May all the beauty be blessed.
KSkun 2022 年 3 月 10 日 于武汉

By KSkun, 2020/12
注:由于本文章面向非专业读者,其中的描述可能不够准确。需要获取准确的说明请阅读参考资料等。
随机数是一种在各种行业中被广泛应用的工具。在密码学中,我们利用随机数生成随机密钥;在图形学中,我们利用随机数进行蒙特卡洛积分,计算渲染的结果;在统计学中,我们利用随机数进行抽样调查,减小统计的工作量。
对于随机数的不同用途,我们对随机数的要求不一,因此随机数也存在着多种定义[1]:

以上三个随机数的条件是逐渐增强的,获得它们的难度也是逐渐增加的。因此我们需要面向随机数的使用场景选择合适的随机数产生方式,以实现安全性与性能的最佳匹配。
真随机数生成器(True Random Number Generator,TRNG)用于生成真正的随机数,即不可预测、不可重现的随机数。目前应用中的真随机数大多来自于物理定律保证的随机性,根据原理可以分为量子和经典两种类型。接下来分别简单介绍两种随机性的采集。[3]
量子随机性的来源主要可以分为两类:原子或更小尺度的量子现象,如原子的衰变;或热噪声,如气体分子的碰撞。以下是一些可以被采集的量子随机性源:
经典随机性通常来源于热现象,但由于温度越高热现象越剧烈,降低温度可能会减少热随机性。以下是一些可以被采集的热随机性源:
Linux 中存在两个与随机数相关的虚拟设备:/dev/random 与 /dev/urandom。这两个设备可以输出随机比特流,用户也可以通过输入数据增加其熵池中的熵。两个设备的区别是,当熵池中的熵低到一定程度时,前者会阻塞并等待熵增加,后者则不会阻塞,但可能导致输出的随机性较差。
Linux 的这些设备可以认为是真随机数生成器。其随机性来源自计算机系统运行中的噪声,具体而言,是 IO 操作的时间戳。磁盘、网络以及键盘、鼠标等设备的输入时间戳会被捕捉,并截取其毫秒或微秒部分的数值,这一部分的数值通常具有随机性。[5]
采集到随机性后,系统将其与熵池中的现有熵进行一系列数学组合,增加熵池中的熵。在生成随机数时,系统使用 SHA-1 对整个熵池计算散列值,这个值便是随机数的输出。
蒙特卡洛方法往往需要均匀分布在一定空间中的随机数,准随机数生成器(Quasi-Random Number Generator,QRNG)便是用于生成这样一系列随机数的工具。具体而言,常用的准随机数序列包括:Halton 序列、Sobol 序列等。[6][7]这些序列在选取不同参数时,呈现出低相关性,因此可以用于生成随机数。
我们先给出 Van der Corput 序列的定义:给定一个正整数 $b$ 作为基,对于一个整数 $i$,其可表示为 $b$ 进制数 $i=\sum a_l(i) b^l$,则 Van der Corput 序列可以由正整数序列通过下列变换获得
$$ \mathbf{\Phi}_b(i) = (b^{-1} \ b^{-2} \ \cdots \ b^{-M}) \cdot (a_0(i) \ a_1(i) \ \cdots \ a_{M-1}(i))^{\mathbf{T}} = \sum a_l(b)\cdot b^{-(l+1)} $$
这可以看做将一个数字的 进制表示镜像翻转到小数点右侧,如下图所示是一个以 2 为基的 Van der Corput 序列的一部分:
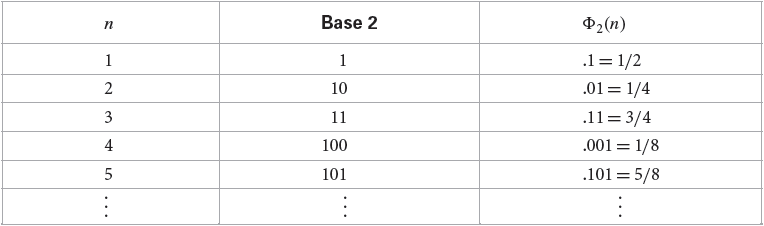
容易发现,这个序列的每一个点都是取目前最长的未覆盖区域的中点,因此具有平均分布的特性。
Halton 序列通过下式生成:
$$ \boldsymbol{X}_i = (\mathbf{\Phi}_{b_1}(i) \ \mathbf{\Phi}_{b_2}(i) \ \cdots \ \mathbf{\Phi}_{b_n}(i)) $$
其中,$b_1, b_2, \dots, b_n$ 取一些互质的质数。由于每一维都是一个 Van der Corput 序列,如此得到的 $n$ 维空间中的一些点在每一维上都是均匀分布的,因此其也具有均匀分布的性质。
而 Hammersley 点集通过下式生成:
$$ \boldsymbol{X}_i = \left(\dfrac{i}{N} \ \mathbf{\Phi}_{b_1}(i) \ \mathbf{\Phi}_{b_2}(i) \ \cdots \ \mathbf{\Phi}_{b_{n-1}}(i)\right) $$
它和 Halton 序列的区别只有第一维是 上均匀分布的,由于这一区别,其平均分布的性质较 Halton 序列更好。此外,生成 Hammersley 点集需要知道样本点的总数量。下图展示了数量为 100 的二维 Halton 序列和 Hammersley 点集的分布状况:

这些序列的缺点是,当基数选取的较大时,生成的前一些点容易呈线性相关性,如基为 17、19 的 Halton 序列的前 16 项为 $(1/17, 1/19), (2/17, 2/19), \dots, (16/17, 16/19)$。为了避免此问题,通常可以丢弃生成的前一些点,或使用一些手段打乱序列的顺序。打乱顺序并不会影响序列的平均分布性质和无关性。[8]
让我们修改一下 Van der Corput 序列的生成方式,在翻转之前先乘以一个生成矩阵 $\mathbf{C}$,即:
$$ \mathbf{\Phi}_{b,\mathbf{C}}(i) = (b^{-1} \ b^{-2} \ \cdots \ b^{-M}) \cdot [\mathbf{C} \cdot (a_0(i) \ a_1(i) \ \cdots \ a_{M-1}(i))^{\mathbf{T}}] $$
而 Sobol 序列则可以通过下式生成:
$$ \boldsymbol{X}_i = (\mathbf{\Phi}_{2,\mathbf{C}_1}(i) \ \mathbf{\Phi}_{2,\mathbf{C}_2}(i) \ \cdots \ \mathbf{\Phi}_{2,\mathbf{C}_n}(i)) $$
即,Sobol 序列的每一维都是以 2 为基的,带不同生成矩阵的类似 Van der Corput 序列。它也具有均匀分布性质,且是对于每一维的 2 的幂次等分区域都会恰好有一个样本点。为了得到分布良好的数列,且避免类似 Halton 序列前几个点出现的线性相关性,生成矩阵需要精心设计,可以在相关资料中获取设计好的生成矩阵。
真随机数的获得需要采集物理现象,准随机数的获得可能需要大量运算,生成这些随机数的成本都较高。为了适应需要快速获得随机数的场景,我们可以降低对随机数性质的要求,则伪随机数生成器(Pseudo Random Number Generator,PRNG)就被提了出来。它用于生成近似具有随机数分布的特性,但可能可以通过分析预测的伪随机数,出于性能考量,其算法具有快速计算的特征。[9]
线性同余生成器(Linear Congruential Generator,LCG)生成随机数的原理基于一个迭代公式:
$$ X_{n+1}=(aX_n+c) \bmod m $$
这种算法在早期是最常用的随机数生成算法,因为其计算简单,且当时并没有发现更好的方法。例如,C 中的 rand() 函数便是以这种方法实现的。[10]
这一方法产生的随机数周期与参数 $a, c, m$ 值的选取有关,根据取模运算的性质,这一算法生成随机数的周期最多为 $m$,因此存在周期较小的问题。[11]
梅森旋转算法(Mersenne Twister,MT)是一种于 1997 年新发明的伪随机数生成算法。该算法的运算非常适合计算,且周期达到了 $2^{19937}-1$ 规模,这个数字被称作梅森质数(Mersenne Prime),这也是该算法名的由来。[13]
为了清晰地分析 MT 算法的流程,我们先给出一个伪随机数生成器的抽象工作流程:
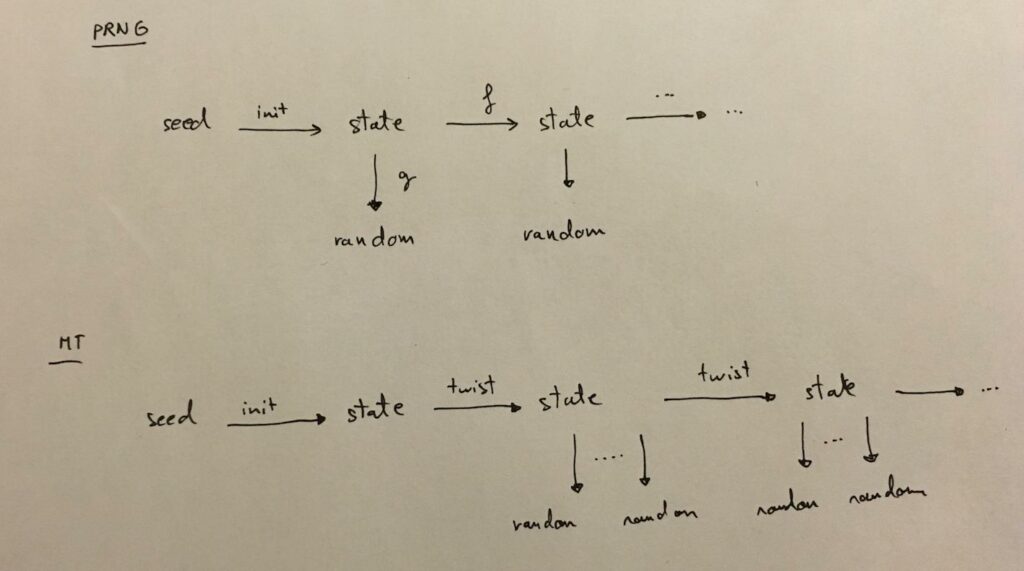
如图所示,我们先用种子(seed)初始化一个初始状态,此时可以通过一个生成函数从状态中生成随机数,生成后通过一个转换函数将当前状态转换成下一个状态。在 MT 中,生成随机数的函数被称为 temper,转换状态的函数被称为 twist。接下来我们按照工作流的先后顺序解释算法各部分的流程[13][15],下面给出了 MT 的全流程示意图,读者也可以结合该图理解。
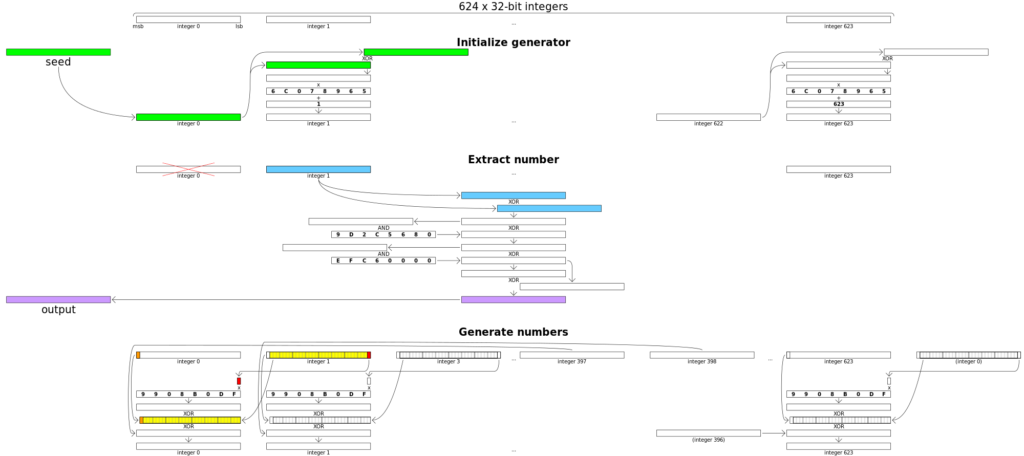
MT 算法的工作区包含 $n$ 个 $w$ 位整数组成的数组 $x_0, x_1, \dots, x_{n-1}$,初始化的工作即是通过种子计算出这些整数的值。下式用于迭代地计算这些整数的值:
$$ x_i=f \cdot {x_{i-1} \oplus [x_{i-1} \gg (w-2)]} + i $$
其中,$\oplus$ 表示按位异或,$\gg$ 表示二进制右移,$\cdot$ 表示常规的整数乘法。通过上式即可获得初始状态的数值,但初始状态不能直接用于生成随机数,必须要经过一次 twist 转换到下一状态。
twist 是 MT 的状态转换函数,其通过下式迭代地计算下一状态的值:
$$ x_{k+n} = x_{k+m} \oplus [(\operatorname{upperbits}x_k || \operatorname{lowerbits}x_{k+1}) \cdot \mathbf{A}] \ (\text{for } k: \ 0\rightarrow n-1)$$
其中,$\operatorname{upperbits}$ 代表该整数的高 $w-r$ 位(低位填 0),$\operatorname{lowerbits}$ 代表该整数的低 $r$ 位(高位填 0),$||$ 代表二进制或,在这里的作用是将高位和低位组合起来,其他记号同上。通过上式计算出的 $x_n, x_{n+1}, \dots, x_{2n-1}$ 即为下一状态的值。
这里的 $\mathbf{A}$ 是一个矩阵,如果将一个 $w$ 位的整数看成是 $w$ 维的向量,则上式中则是令此向量乘上矩阵 $\mathbf{A}$。该矩阵定义如下:
$$ \mathbf{A} = \begin{pmatrix} 0 & \mathbf{I}_{w-1} \\ a_{w-1} & (a_{w-2}, \dots, a_0) \end{pmatrix} $$
则乘上该矩阵的作用等效为下式:
$$ x\mathbf{A} = \begin{cases} x \gg 1, & x_0=0, \\ (x \gg 1) \oplus a, & x_0=1. \end{cases} $$
这一操作的设计将在之后提到。
容易发现,MT 的一个状态包括了 $n$ 个整数 $x_0, x_1, \dots, x_{n-1}$,其中每一个整数都可以用于产生一个随机数,因此一个状态共可以产生 $n$ 个随机数。产生随机数时,我们取出下一个未使用的数字 $x_m$,并进行如下操作:
$$ \begin{cases} y=x\oplus[(x\gg u)\&d] \\ y=y\oplus[(y\ll s)\&b] \\ y=y\oplus [(y\ll t)\& c] \\ z=y\oplus (y\gg l) \end{cases} $$
其中 $u, s, t, b, c, d$ 都是参数,$\ll$ 和 $\gg$ 分别代表二进制左移和右移,$\&$ 代表按位与。操作后产生的 $z$ 即为此次生成的随机数。
为了解释 MT 算法的核心操作 twist,我们首先要引入一个概念:线性反馈移位寄存器(Linear Feedback Shifting Register,LFSR)。
学过数电的同学对移位寄存器的概念并不陌生,该寄存器支持存储几个位,并支持将存储的位进行左移或右移,空出来的一位通过外部输入的信号指定。而 LFSR 则是将空出来的一位通过一个反馈函数进行迭代异或来指定的,因此被称作线性反馈。
对于一个 4 位的 LFSR,有反馈函数 $f(x)=x^4+x^2+x+1$ ,则反馈应该通过高 4、2、1 位迭代异或后生成,即 $a_{\text{new}}=a_3\oplus a_1\oplus a_0$。令其初始状态为 1000,则迭代进行向右移位,其状态变化:1000→1100→1110→0111→0011→0001→1000。容易发现此处形成了一个长为 6 的状态环。
对于一个 $w$ 位的 LFSR,其最多有 $2^w$ 种可能的状态,其中全 0 是无效状态,因此有 $2^w-1$ 种有效状态。当反馈函数 $f(x)$ 满足某些条件时,可以让 LFSR 的状态环长度达到最大值 $2^w-1$。

让我们回头来看 twist 的流程,它包含一个迭代进行的递推式,如果将 $x_{k+n}$ 看做 $x_{k-1}$,则可以认为 $x_{k+n}$ 便是其中的反馈位,该反馈位通过 $x_k$ 的高位和 $x_{k+1}$ 的低位拼接,再与 $x_{k+m}$ 进行迭代异或得到。因此 MT 可以看做一个 $nw-r$ 位的线性反馈移位寄存器,一次 twist 本质上在做 $w$ 次原子化的反馈移位。根据上面我们得到的结论,MT 的周期最大可达 $2^{nw-r}-1$,一组精心设计的参数可以令其达到梅森质数的周期大小,作为参考,MT19937 的参数为:

基于上述过程,容易发现,MT 的运算大多为简单的加、乘与位运算,对于 CPU 而言这些运算比取模、浮点数与矩阵更快,因此 MT 是高效率的。MT 的周期高达 $2^{19937}-1$,在一般应用中可以不用考虑其周期问题,因此 MT 是性质好的。这就是为什么现在主流的随机数算法都采用了 MT19937,其中包括 C++11 中引入的 std::mt19937。
一个 MT19937 的 C++ 实现可以参见参考资料的 [16]。
2003 年发明的 Xorshift 随机数生成器系列也基于 LSFR,但并没有 MT 中那么复杂的规则。它通过多次异或移位后的状态来生成随机数,移位的规则需要精心构造才能保证随机数的性质。
例如,下面是一个最简单的 32 位 Xorshift 随机数生成器的 C 源代码[17]:
#include <stdint.h>
struct xorshift32_state {
uint32_t a;
};
/* The state word must be initialized to non-zero */
uint32_t xorshift32(struct xorshift32_state *state)
{
/* Algorithm "xor" from p. 4 of Marsaglia, "Xorshift RNGs" */
uint32_t x = state->a;
x ^= x << 13;
x ^= x >> 17;
x ^= x << 5;
return state->a = x;
}随机数的一个应用便是在图形学中广泛存在的蒙特卡洛方法。蒙特卡洛方法通过随机采样对函数的积分值进行估计,从而快速计算出一些不便计算的积分值,且估计的过程可以并行化,便于在 GPU 上计算。
在这一节中将介绍全局光照渲染的光线追踪方法,来展现随机数与蒙特卡洛方法在图形学中的应用。[18][19]
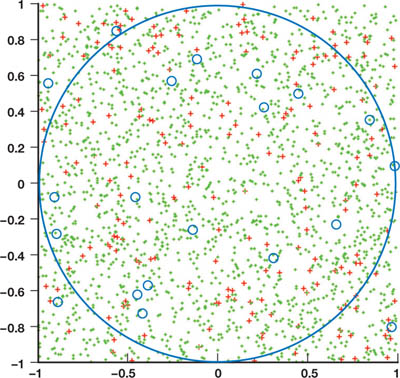
蒙特卡洛方法(Monte Carlo Method)是一种通过随机采样进行大量实验,根据实验结果来计算不易计算的积分结构或得到概率分布等。根据大数定理,蒙特卡洛方法在采样数越大的时候,估计结果越接近真实值。
下面以一个例子来理解蒙特卡洛方法。利用蒙特卡洛方法可以求圆周率 π,我们画一个半径为 1、圆心在原点的圆,并取其右上角在 (1, 1) 的外切正方形,接下来在 $(-1,1)^2$ 空间中随机取一些样本点,利用点到圆心的距离判断是否在圆内。假设总样本数为 $n$,在圆内的样本数为 $m$,则圆与外切正方形的面积之比为 $\dfrac{m}{n}$,而 π 可以根据下式求出:
$$ \pi = \dfrac{m}{n} \cdot 2^2 $$
在本例中,我们只介绍较为简单的模型。
如上图所示,我们想求出观测者观测到给定点 $p$ 的亮度值 $L_o(p, \omega_0)$,其中 $\omega_0$ 为给定点 $p$ 出射到观测者的光线角度。考虑光线入射到 $p$ 点后发生反射,再出射到观测者眼中,则我们可以反着找出哪些入射光可以反射到观测者眼中即可。
给定一个入射角度 $\omega_i$,要找出入射光强 $L_i(p, \omega_i)$ 是简单的,根据光沿直线传播的原理,可以考虑反着求出该光的传播路径,即反着射出一束光,如果路径与某一光源相交,则该光的入射光强可通过光源参数求出。
由于 $p$ 点的反射性质存在漫反射成分,入射角度具有连续的取值区间。假设 $p$ 点自身不发光,则下式可以表示 $p$ 点出射的亮度:
$$ L_o(p,\omega_0) = \int L_i(p,\omega_i)f_r(p,\omega_i,\omega_o) \mathrm{d}S$$
此积分值往往较复杂,在实时渲染中通常采用蒙特卡洛方法快速计算出积分的值。即,从取值区间中取出随机样本,对于每一个角度进行光线追踪,并对所有追踪得到的亮度值求平均叠加。在实际应用中,样本数越多,则积分精度越高,渲染效果越接近理想的物理效果。
GPU 在计算上述流程时,可以并行地生成多组相关度低的随机数作为样本,之后并行地对大量样本进行追踪和计算,随机数生成与蒙特卡洛方法的并行性和高效性在此充分展现出来。
本文的灵感来源为 NVIDIA Developer 上的一篇文章《Efficient Random Number Generation and Application Using CUDA》(参考资料 [18]),该文章启发我学习与研究各种随机数生成算法及其特征,以及文章本身提到的 GPU 上的随机数生成与随机数在图形学中的应用。
随机数是生活中常见的概念,但生活中的随机概念一般基于我们的定性认识。本文尝试从数学与计算机科学的角度研究随机数与其应用,大概介绍了常用的各类随机数与一个随机数在图形学中的应用实例,以期读者能建立对随机数的系统认知。
本文参考了大量网络与文献资料,在此对这些资料的贡献者表示感谢。
Copyright © 2017-2022 KSkun's Blog.
Authored by KSkun and his friends.

本博客内所有原创内容采用知识共享署名-相同方式共享 4.0 国际许可协议进行许可。引用内容如果侵权,请在此留言。
All original content in this blog is licensed under a Creative Commons Attribution-ShareAlike 4.0 International License.
If any reference content infringes your rights, please contact us.






{kind=link}
{kind=link}